Preparativos
Carga de paquetes
Conjuntos de datos utilizados
Provincias de Costa Rica# Lectura mediante st_read()
provincias <-
st_read(
"https://raw.githubusercontent.com/gf0604-procesamientodatosgeograficos/2021i-datos/main/ign/delimitacion-territorial-administrativa/cr_provincias_simp_wgs84.geojson",
quiet = TRUE
)
# Mapeo
plot(provincias$geometry)
# Lectura mediante st_read()
cantones <-
st_read(
"https://raw.githubusercontent.com/gf0604-procesamientodatosgeograficos/2021i-datos/main/ign/delimitacion-territorial-administrativa/cr_cantones_simp_wgs84.geojson",
quiet = TRUE
)
# Mapeo
plot(cantones$geometry)
Documentación del paquete spData: Datasets for Spatial Analysis - spData.
Introducción
Se les llama atributos a los elementos de datos no espaciales de un conjunto de datos geográficos. Un conjunto de datos vectoriales puede tener asociados varios campos de atributos, mientras que un conjunto de datos raster tiene solamente uno.
Datos vectoriales
Las operaciones con atributos en datos vectoriales incluyen:
- Creación de subconjuntos (subsetting).
- Agregación (aggregation).
- Cruce de datos (joining).
Seguidamente, se explicará como maneja estas operaciones el paquete sf.
Manejo de datos de atributos con el paquete sf
El paquete sf define una clase, también llamada sf, la cual extiende la clase data.frame del paquete base de R. Los objetos de la clase sf tienen un registro (o feature) por cada observación y una columna por cada atributo. También tienen una columna especial para almacenar las geometrías (puntos, líneas, polígonos, etc.), la cual generalmente se denomina geometry o geom. Esto permite que sf utilice métodos (i.e. funciones) de la clase data.frame, tales como plot() y summary(), entre otros.
La lista de métodos de sf puede obtenerse a través de la función methods():
# Métodos de la clase sf
methods(class = "sf")
[1] $<- [ [[<-
[4] aggregate anti_join arrange
[7] as.data.frame cbind coerce
[10] dbDataType dbWriteTable distinct
[13] dplyr_reconstruct extent extract
[16] filter full_join group_by
[19] group_split identify initialize
[22] inner_join left_join mask
[25] merge mutate plot
[28] print raster rasterize
[31] rbind rename right_join
[34] rowwise sample_frac sample_n
[37] select semi_join show
[40] slice slotsFromS3 st_agr
[43] st_agr<- st_area st_as_s2
[46] st_as_sf st_bbox st_boundary
[49] st_buffer st_cast st_centroid
[52] st_collection_extract st_convex_hull st_coordinates
[55] st_crop st_crs st_crs<-
[58] st_difference st_filter st_geometry
[61] st_geometry<- st_inscribed_circle st_interpolate_aw
[64] st_intersection st_intersects st_is
[67] st_is_valid st_join st_line_merge
[70] st_m_range st_make_valid st_nearest_points
[73] st_node st_normalize st_point_on_surface
[76] st_polygonize st_precision st_reverse
[79] st_sample st_segmentize st_set_precision
[82] st_shift_longitude st_simplify st_snap
[85] st_sym_difference st_transform st_triangulate
[88] st_union st_voronoi st_wrap_dateline
[91] st_write st_z_range st_zm
[94] summarise transform transmute
[97] ungroup
see '?methods' for accessing help and source codeAdemás de data.frame, sf es compatible con clases como las del paquete tibble, las cuales pueden manipularse mediante los métodos de dplyr. Esto que permite un manejo tidy (ordenado, organizado) de los datos geoespaciales, de acuerdo con el enfoque de Tidyverse.
Funciones básicas para manejo de data frames y objetos sf
Funciones para obtener información básica de un data frame o de un objeto sf:
# Clase de cantones
class(cantones)
[1] "sf" "data.frame"# Dimensiones (cantidad de filas y de columnas)
dim(cantones)
[1] 82 10# Cantidad de filas (i.e. observaciones)
nrow(cantones)
[1] 82# Cantidad de columnas (i.e. variables)
ncol(cantones)
[1] 10# Nombres de las columnas
names(cantones)
[1] "gmlid" "cod_catalo" "cod_canton" "canton" "ori_toponi"
[6] "area" "cod_provin" "provincia" "version" "geometry" La función st_drop_geometry() puede ser útil cuando, por ejemplo, solo se necesita trabajar con los atributos y la columna con la geometría consume demasiada memoria del computador.
# Remoción de la columna de geometría
cantones_df <- st_drop_geometry(cantones)
# Nombres de las columnas
names(cantones_df)
[1] "gmlid" "cod_catalo" "cod_canton" "canton" "ori_toponi"
[6] "area" "cod_provin" "provincia" "version" # Clase de df_cantones (nótese como no se muestra ya la clase sf)
class(cantones_df)
[1] "data.frame"# Tamaño del conjunto de datos original (tipo sf)
print(object.size(cantones), units="Kb")
1812.6 Kb# Tamaño del conjunto de datos sin geometrías (tipo data.frame)
print(object.size(cantones_df), units="Kb")
35.4 KbTambién es posible ocultar la columna de geometría de un conjunto de datos (sin borrarla) mediante el argumento drop = TRUE.
# Sin drop = TRUE
cantones[1:10, c("canton", "area")]
Simple feature collection with 10 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -84.55536 ymin: 8.040251 xmax: -82.55287 ymax: 9.767778
Geodetic CRS: WGS 84
canton area geometry
1 Corredores 623.61 MULTIPOLYGON (((-82.94161 8...
2 Golfito 1753.42 MULTIPOLYGON (((-83.46678 8...
3 Coto Brus 944.24 MULTIPOLYGON (((-82.90501 8...
4 Osa 1932.03 MULTIPOLYGON (((-83.83946 9...
5 Buenos Aires 2382.94 MULTIPOLYGON (((-83.32101 9...
6 Pérez Zeledón 1901.08 MULTIPOLYGON (((-83.77329 9...
7 Quepos 557.85 MULTIPOLYGON (((-84.13572 9...
8 Talamanca 2792.23 MULTIPOLYGON (((-82.89452 9...
9 Parrita 483.22 MULTIPOLYGON (((-84.30298 9...
10 Tarrazú 291.27 MULTIPOLYGON (((-83.98178 9...# Con drop = TRUE
cantones[1:10, c("canton", "area"), drop=TRUE]
canton area
1 Corredores 623.61
2 Golfito 1753.42
3 Coto Brus 944.24
4 Osa 1932.03
5 Buenos Aires 2382.94
6 Pérez Zeledón 1901.08
7 Quepos 557.85
8 Talamanca 2792.23
9 Parrita 483.22
10 Tarrazú 291.27Creación de subconjuntos
Frecuentemente, es necesario extrer subconjuntos del conjunto de datos original, para facilidad de manejo y para atender requerimientos específicos de un análisis. En esta sección, se explican las diferentes opciones para creación de subconjuntos, tanto con el paquete base de R como con dplyr. En resumen, estas son:
- Con el paquete base:
- La notación de
[]y$ - La función
subset()
- La notación de
- Con el paquete dplyr:
- La función
select() - La función
slice() - La función
filter()
- La función
Notaciones y funciones del paquete base
La notación de [] y $
La notación de paréntesis cuadrados ([]) y el signo de dólar ($) permite crear subconjuntos con base en la posición de filas y de columnas, por medio de nombres de columnas y a través de la especificación de condiciones (i.e. expresiones lógicas).
# Subconjunto especificado por posiciones de filas
cantones[1:10, ]
# Subconjunto especificado por posiciones de columnas
cantones[, 8:10]
# Subconjunto especificado por nombres de columnas
cantones[, c("canton", "area", "provincia")]
Especificación mediante una condición (i.e. expresión lógica):
# Cantones de la provincia de Cartago
cantones[cantones$provincia == "Cartago", c("canton", "provincia"), drop = TRUE]
canton provincia
19 El Guarco Cartago
20 Cartago Cartago
22 Paraíso Cartago
23 Jiménez Cartago
24 Turrialba Cartago
26 Oreamuno Cartago
29 La Unión Cartago
34 Alvarado CartagoLa función subset()
La función subset() también retorna un subconjunto cuyos registros cumplen una condición.
canton area
5 Buenos Aires 2382.94
8 Talamanca 2792.23
70 Pococí 2408.76
71 San Carlos 3352.31
74 Sarapiquí 2144.38Los operadores lógicos y de comparación que pueden utilizarse en las condiciones de la función subset(), y en expresiones lógicas en general, se listan en la siguiente tabla:
| Operador | Descripción |
|---|---|
| == | igual a |
| != | distinto de |
| >, < | mayor que, menor que |
| >=, <= | mayor o igual que, menor o igual que |
| &, |, ! | Operadores lógicos: y, o, no |
Funciones del paquete dplyr
Las funciones del paquete base de R son confiables y ampliamente usadas. Sin embargo, el enfoque más moderno de dplyr permite flujos de trabajo más intuitivos y es más rápido, debido a que se apoya en código escrito en el lenguaje C++. Esto es útil, por ejemplo, cuando se trabaja con conjuntos de datos grandes (big data) y cuando se necesita integración con bases de datos. Las principales funciones de dplyr para creación de subconjuntos son select(), slice() y filter().
La función select()
La función select() permite seleccionar y renombrar columnas de un conjunto de datos.
# Selección de columnas
cantones %>%
select(canton, provincia)
Simple feature collection with 82 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -87.10189 ymin: 5.498569 xmax: -82.55287 ymax: 11.21964
Geodetic CRS: WGS 84
First 10 features:
canton provincia geometry
1 Corredores Puntarenas MULTIPOLYGON (((-82.94161 8...
2 Golfito Puntarenas MULTIPOLYGON (((-83.46678 8...
3 Coto Brus Puntarenas MULTIPOLYGON (((-82.90501 8...
4 Osa Puntarenas MULTIPOLYGON (((-83.83946 9...
5 Buenos Aires Puntarenas MULTIPOLYGON (((-83.32101 9...
6 Pérez Zeledón San José MULTIPOLYGON (((-83.77329 9...
7 Quepos Puntarenas MULTIPOLYGON (((-84.13572 9...
8 Talamanca Limón MULTIPOLYGON (((-82.89452 9...
9 Parrita Puntarenas MULTIPOLYGON (((-84.30298 9...
10 Tarrazú San José MULTIPOLYGON (((-83.98178 9...# Selección y cambio de nombre de columnas
cantones %>%
select(canton, area_km2 = area, provincia)
Simple feature collection with 82 features and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -87.10189 ymin: 5.498569 xmax: -82.55287 ymax: 11.21964
Geodetic CRS: WGS 84
First 10 features:
canton area_km2 provincia geometry
1 Corredores 623.61 Puntarenas MULTIPOLYGON (((-82.94161 8...
2 Golfito 1753.42 Puntarenas MULTIPOLYGON (((-83.46678 8...
3 Coto Brus 944.24 Puntarenas MULTIPOLYGON (((-82.90501 8...
4 Osa 1932.03 Puntarenas MULTIPOLYGON (((-83.83946 9...
5 Buenos Aires 2382.94 Puntarenas MULTIPOLYGON (((-83.32101 9...
6 Pérez Zeledón 1901.08 San José MULTIPOLYGON (((-83.77329 9...
7 Quepos 557.85 Puntarenas MULTIPOLYGON (((-84.13572 9...
8 Talamanca 2792.23 Limón MULTIPOLYGON (((-82.89452 9...
9 Parrita 483.22 Puntarenas MULTIPOLYGON (((-84.30298 9...
10 Tarrazú 291.27 San José MULTIPOLYGON (((-83.98178 9...La función slice()
slice() es el equivalente de select() para filas. Crea un subconjunto con base en las posiciones de las filas.
# Subconjunto especificado mediante un rango de filas
cantones %>%
slice(1:10)
La función filter()
La función filter() es el equivalente en dplyr de la función subset() del paquete base. Retorna los registros que cumplen con una condición.
# Androides de "La Guerra de las Galaxias"
starwars %>%
filter(species == "Droid")
# A tibble: 6 x 14
name height mass hair_color skin_color eye_color birth_year sex
<chr> <int> <dbl> <chr> <chr> <chr> <dbl> <chr>
1 C-3PO 167 75 <NA> gold yellow 112 none
2 R2-D2 96 32 <NA> white, bl~ red 33 none
3 R5-D4 97 32 <NA> white, red red NA none
4 IG-88 200 140 none metal red 15 none
5 R4-P17 96 NA none silver, r~ red, blue NA none
6 BB8 NA NA none none black NA none
# ... with 6 more variables: gender <chr>, homeworld <chr>,
# species <chr>, films <list>, vehicles <list>, starships <list>Las funciones del paquete dplyr suelen ser utilizadas conjuntamente con el operador pipe (%>%), el cual posibilita el “encadenamiento” de funciones: la salida de la función previa se convierte en el primer argumento de la siguiente función. En el siguiente ejemplo, el conjunto de datos starwars se pasa como entrada a la función filter(), para filtrar los personajes humanos. Seguidamente, el resultado se pasa a la función select(), para seleccionar las columnas name, homeworld y species. Finalmente, la función slice() reduce el resultado a las 10 primeras filas.
# Encadenamiento de funciones mediante pipe (%>%)
starwars %>%
filter(species == "Human") %>%
select(name, homeworld, species) %>%
slice(1:10)
# A tibble: 10 x 3
name homeworld species
<chr> <chr> <chr>
1 Luke Skywalker Tatooine Human
2 Darth Vader Tatooine Human
3 Leia Organa Alderaan Human
4 Owen Lars Tatooine Human
5 Beru Whitesun lars Tatooine Human
6 Biggs Darklighter Tatooine Human
7 Obi-Wan Kenobi Stewjon Human
8 Anakin Skywalker Tatooine Human
9 Wilhuff Tarkin Eriadu Human
10 Han Solo Corellia Human Una alternativa al uso de pipes es el anidamiento de las funciones:
# Anidamiento de funciones
slice(
select(
filter(
starwars,
species=="Human"
),
name, homeworld, species
),
1:10
)
# A tibble: 10 x 3
name homeworld species
<chr> <chr> <chr>
1 Luke Skywalker Tatooine Human
2 Darth Vader Tatooine Human
3 Leia Organa Alderaan Human
4 Owen Lars Tatooine Human
5 Beru Whitesun lars Tatooine Human
6 Biggs Darklighter Tatooine Human
7 Obi-Wan Kenobi Stewjon Human
8 Anakin Skywalker Tatooine Human
9 Wilhuff Tarkin Eriadu Human
10 Han Solo Corellia Human Ejercicio: mediante las funciones select() y filter() de dplyr, cree un nuevo objeto sf que contenga los cantones de Puntarenas y Guanacaste con área mayor o igual a 2000 km2. Incluya las columnas de provincia, cantón y área.
Agregación de datos
Las operaciones de agregación realizan cálculos (suma, promedio, etc.) a partir de la agrupación de valores de variables. En esta sección, se explican funciones de agregación contenidas en los paquetes stats, sf y dplyr, las cuales son:
- Del paquete stats:
- La función
aggregate()
- La función
- Del paquete sf:
- La función
aggregate()
- La función
- Del paquete dplyr:
- La función
summarize()
- La función
La función aggregate() de stats
La función aggregate() del paquete stats aplica una función de agregación (ej. suma, promedio, mínimo, máximo) sobre una columna. El resultado es un objeto de tipo data.frame.
# Suma de áreas de cantones por provincia
aggregate(
data = cantones,
area ~ provincia,
FUN = sum,
na.rm = TRUE
)
provincia area
1 Alajuela 9772.25
2 Cartago 3093.23
3 Guanacaste 10196.30
4 Heredia 2663.45
5 Limón 9176.97
6 Puntarenas 11298.51
7 San José 4969.73La función aggregate() de sf
aggregate() es una función genérica, lo que significa que pueden comportarse de manera diferente, dependiendo de los valores de entrada. El paquete sf también provee una versión de aggregate(), la cual se activa cuando recibe un objeto sf y se usa el argumento by. El resultado es un objeto de tipo sf.
# Suma de áreas de cantones por provincia
aggregate(
cantones["area"],
by = list(cantones$provincia),
FUN = sum,
na.rm = TRUE
)
Simple feature collection with 7 features and 2 fields
Attribute-geometry relationship: 0 constant, 1 aggregate, 1 identity
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -87.10189 ymin: 5.498569 xmax: -82.55287 ymax: 11.21964
Geodetic CRS: WGS 84
Group.1 area geometry
1 Alajuela 9772.25 POLYGON ((-85.01616 10.6717...
2 Cartago 3093.23 POLYGON ((-84.02189 9.77001...
3 Guanacaste 10196.30 MULTIPOLYGON (((-85.79855 1...
4 Heredia 2663.45 POLYGON ((-84.11004 9.96061...
5 Limón 9176.97 POLYGON ((-83.60509 9.98186...
6 Puntarenas 11298.51 MULTIPOLYGON (((-87.10174 5...
7 San José 4969.73 POLYGON ((-84.48391 9.57367...La función summarize() de dplyr
La función summarize() es el equivalente de aggregate() en el paquete dplyr. Suele utilizarse conjuntamente con group_by(), que especifica la variable a agrupar.
# Suma de áreas de cantones por provincia
cantones %>%
group_by(provincia) %>%
summarize(area_km2 = sum(area, na.rm = TRUE))
Simple feature collection with 7 features and 2 fields
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -87.10189 ymin: 5.498569 xmax: -82.55287 ymax: 11.21964
Geodetic CRS: WGS 84
# A tibble: 7 x 3
provincia area_km2 geometry
<chr> <dbl> <GEOMETRY [°]>
1 Alajuela 9772. POLYGON ((-85.01616 10.67176, -85.01735 10.6727~
2 Cartago 3093. POLYGON ((-84.02189 9.770014, -84.02291 9.77039~
3 Guanacaste 10196. MULTIPOLYGON (((-85.79855 10.48368, -85.79847 1~
4 Heredia 2663. POLYGON ((-84.11004 9.960612, -84.11185 9.96061~
5 Limón 9177. POLYGON ((-83.60509 9.981863, -83.61626 9.98678~
6 Puntarenas 11299. MULTIPOLYGON (((-87.10174 5.508679, -87.10189 5~
7 San José 4970. POLYGON ((-84.48391 9.573673, -84.48379 9.57302~Nótese que este enfoque permite renombrar las variables, como también se hace en el siguiente ejemplo:
# Suma total de las áreas de cantones
cantones %>%
summarize(area_km2 = sum(area, na.rm = TRUE),
cantidad_cantones = n())
Simple feature collection with 1 feature and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -87.10189 ymin: 5.498569 xmax: -82.55287 ymax: 11.21964
Geodetic CRS: WGS 84
area_km2 cantidad_cantones geometry
1 51170.44 82 MULTIPOLYGON (((-87.10189 5...El siguiente ejemplo utiliza otras funciones del paquete dplyr para encontrar las tres provincias más grandes y sus respectivas áreas:
# Área y cantidad de cantones de las tres provincias más grandes
cantones %>%
select(area, provincia) %>%
group_by(provincia) %>%
summarize(area = sum(area, na.rm = TRUE),
cantidad_cantones = n()) %>%
arrange(desc(area)) %>%
top_n(n = 3, wt = area) %>%
st_drop_geometry()
# A tibble: 3 x 3
provincia area cantidad_cantones
* <chr> <dbl> <int>
1 Puntarenas 11299. 11
2 Guanacaste 10196. 11
3 Alajuela 9772. 16Ejercicio: mediante summarize(), y otras funciones de dplyr, despliegue el área y la cantidad de cantones de las dos provincias más pequeñas.
Cruce de datos
La combinación de datos ubicados en diferentes fuentes es una tarea común en análisis de información. Este tipo de operaciones se realizan con base en atributos que son comunes en los conjuntos de datos que se desea cruzar. El paquete dplyr proporciona varias funciones para realizar cruces de datos, entre las que se encuentran:
- La función
left_join() - La función
inner_join()
La función left_join()
La función left_join() mantiene todos los registros de la tabla del lado izquierdo y agrega las columnas de la tabla del lado derecho, en los registros en los que hay coincidencia.
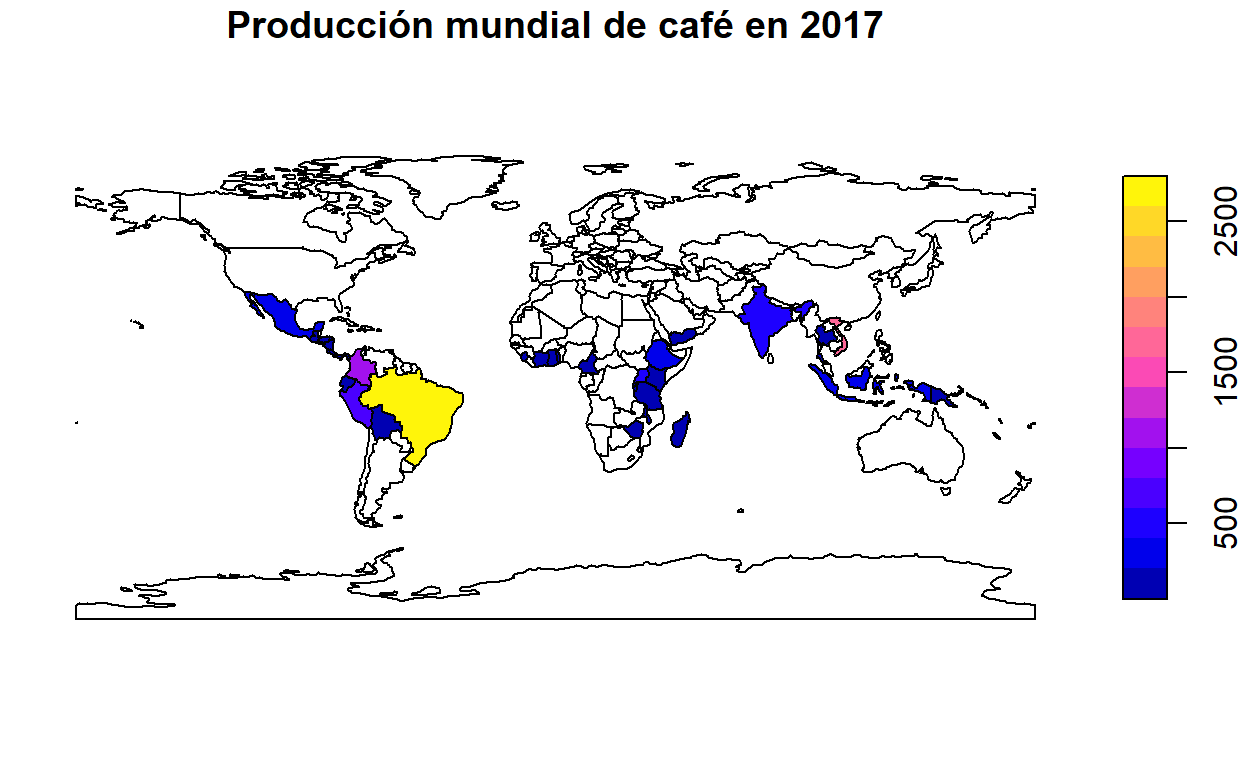
# "Join" de los datos de producción de café. Ambas tablas comparten la columna name_long.
productores_cafe_1 <- left_join(world, coffee_data)
# Mapeo de la producción de café en 2017
plot(productores_cafe_1["coffee_production_2017"], main = "Producción mundial de café en 2017")
La función inner_join()
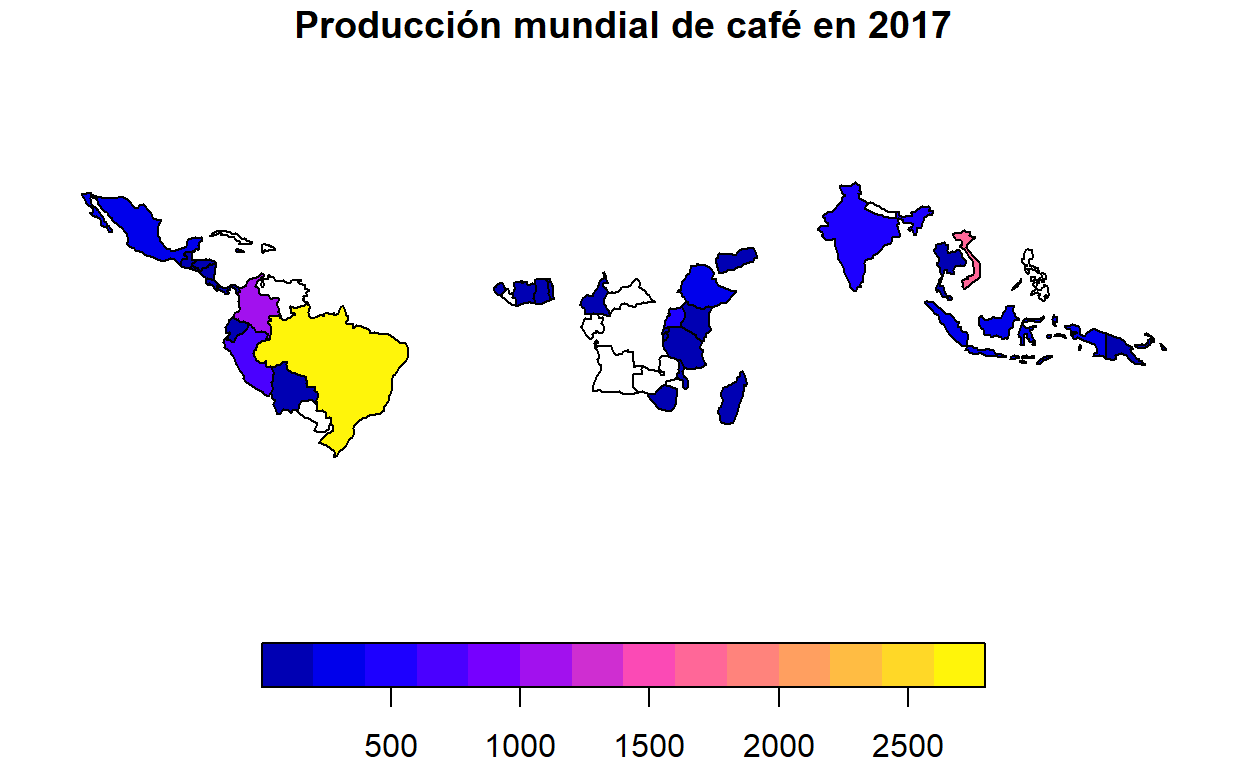
La función inner_join() retorna solamente aquellos registros que coinciden en ambas tablas.
# "Join" de los datos de producción de café. Ambas tablas comparten la columna name_long.
productores_cafe_2 <- inner_join(world, coffee_data)
# Mapeo de la producción de café en 2017
plot(productores_cafe_2["coffee_production_2017"], main = "Producción mundial de café en 2017")
Datos raster
Las operaciones con atributos en datos raster incluyen:
- Creación de subconjuntos (subsetting).
- Resumen de información (summarizing).
Seguidamente, se explicará como maneja estas operaciones el paquete raster.
Manejo de datos de atributos con el paquete raster
Funciones básicas para manejo de objetos raster
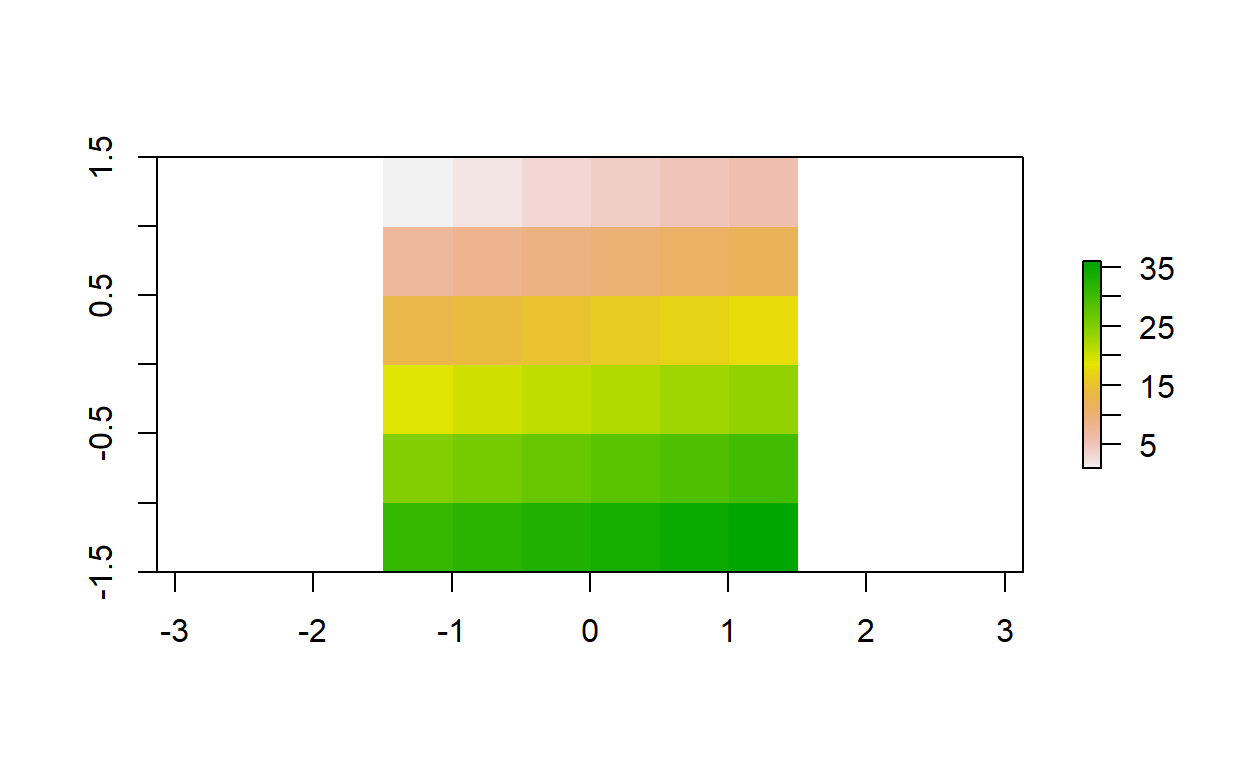
El siguiente bloque de código crea y mapea un objeto raster llamado elevacion.
# Creación del objeto raster
elevacion = raster(
nrows = 6,
ncols = 6,
res = 0.5,
xmn = -1.5,
xmx = 1.5,
ymn = -1.5,
ymx = 1.5,
vals = 1:36
)
# Mapeo
plot(elevacion)
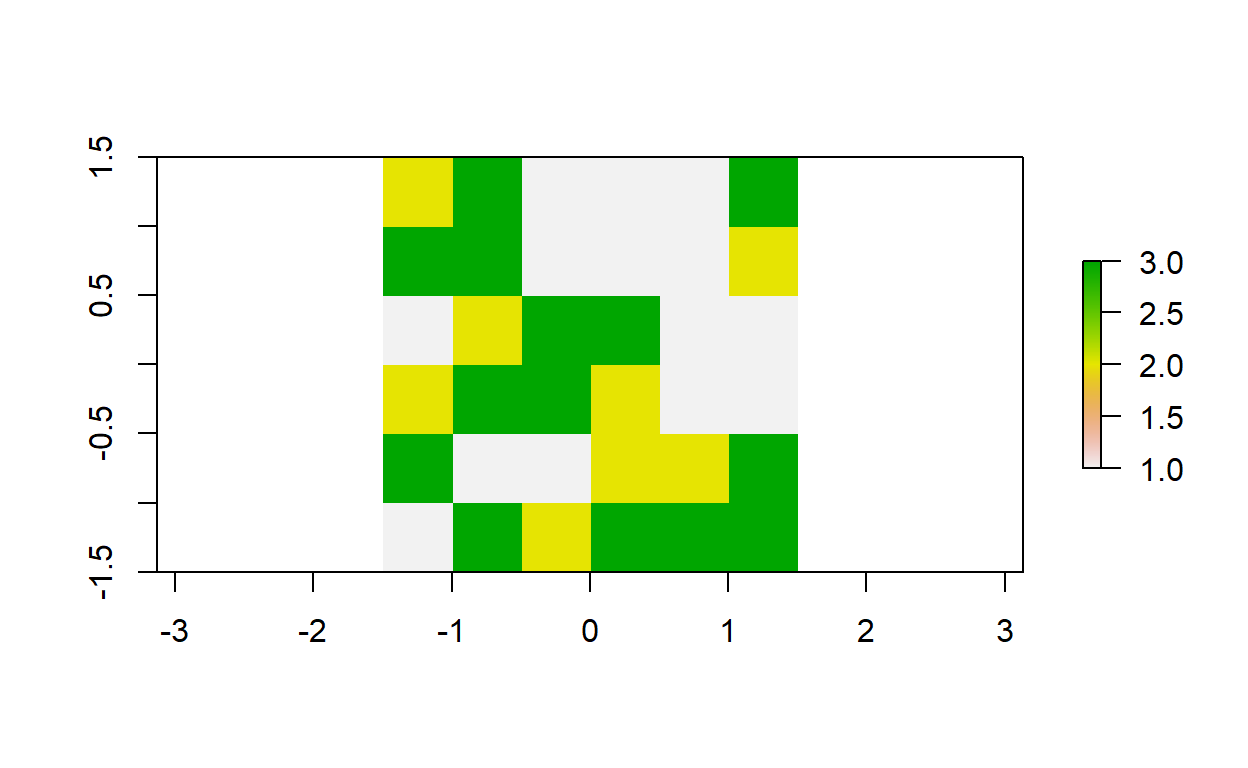
Los objetos raster también pueden contener valores categóricos de tipo logical o factor. El siguiente bloque de código crea y mapea un objeto raster con información sobre tipos de granos de una porción de suelo.
# Tipos de granos
grano_tipo = c("arcilla", "limo", "arena")
# Lista de nombres de granos generada aleatoriamente
grano_nombres = sample(grano_tipo, 36, replace = TRUE)
grano_nombres
[1] "limo" "arena" "arcilla" "arcilla" "arcilla" "arena"
[7] "arena" "arena" "arcilla" "arcilla" "arcilla" "limo"
[13] "arcilla" "limo" "arena" "arena" "arcilla" "arcilla"
[19] "limo" "arena" "arena" "limo" "arcilla" "arcilla"
[25] "arena" "arcilla" "arcilla" "limo" "limo" "arena"
[31] "arcilla" "arena" "limo" "arena" "arena" "arena"
# Factor de tipos de granos
grano_factor = factor(grano_nombres, levels = grano_tipo)
# Objeto raster de tipos de granos
grano = raster(
nrows = 6,
ncols = 6,
res = 0.5,
xmn = -1.5,
xmx = 1.5,
ymn = -1.5,
ymx = 1.5,
vals = grano_factor
)
# Mapeo
plot(grano)
Ambos objetos raster pueden guardados en el disco con la función writeRaster().
# Especificación del directorio de trabajo (debe ser una ruta existente)
setwd("C:/Users/mfvargas/Downloads")
# Escritura de los objetos raster
writeRaster(grano, filename = "elevacion.asc", overwrite = TRUE)
writeRaster(grano, filename = "grano.asc", overwrite = TRUE)
La función levels() puede utilizarse para consultar la Raster Attribute Table (RAT) de un objeto raster, la cual contiene información sobre sus factores y niveles. También puede emplearse para asignar nuevos factores al objeto raster.
# Consulta de la RAT
levels(grano)
[[1]]
ID VALUE
1 1 arcilla
2 2 limo
3 3 arena
# Nuevo factor
levels(grano)[[1]] = cbind(levels(grano)[[1]], humedad = c("mojado", "húmedo", "seco"))
# Consulta de la RAT
levels(grano)
[[1]]
ID VALUE humedad
1 1 arcilla mojado
2 2 limo húmedo
3 3 arena seco
# Consulta de los factores de un subconjunto de celdas del objeto raster
factorValues(grano, grano[c(1, 11, 35)])
VALUE humedad
1 limo húmedo
2 arcilla mojado
3 arena secoCreación de subconjuntos
Los subconjuntos se crean en objetos raster con el operador [, el cual acepta una variedad de entradas.
- Índices de filas y columnas.
- ID de celdas.
- Coordenadas.
- Otros objetos espaciales.
En esta lección, solo se tratarán las dos primeras opciones. Las restantes se cubrirán en las lecciones sobre operaciones espaciales.
Las dos primeras opciones se ilustran en el siguiente bloque de código, en el que se consulta la celda (también llamada pixel) ubicada en la esquina superior izquierda del objeto raster de elevación.
# Celda en la fila 1, columna 1
elevacion[1, 1]
[1] 1# Celda con ID = 1
elevacion[1]
[1] 1La totalidad de los valores del objeto raster puede consultarse con las función values().
# Valores de un objeto raster
values(elevacion)
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
[23] 23 24 25 26 27 28 29 30 31 32 33 34 35 36Estas funciones también pueden utilizarse en objetos raster de múltiples capas (i.e. stack, brick). En el siguiente bloque de código, se muestran el uso de la función raster::subset() y de los operadores [ y $ para consultar capas.
# Creación de un objeto stack de dos capas
r_stack = stack(elevacion, grano)
r_stack
class : RasterStack
dimensions : 6, 6, 36, 2 (nrow, ncol, ncell, nlayers)
resolution : 0.5, 0.5 (x, y)
extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
crs : +proj=longlat +datum=WGS84 +no_defs
names : layer.1, layer.2
min values : 1, 1
max values : 36, 3
# Cambio de nombres de las capas
names(r_stack) = c("elevacion", "grano")
# Tres maneras de extraer una capa de un objeto stack
raster::subset(r_stack, "elevacion")
class : RasterLayer
dimensions : 6, 6, 36 (nrow, ncol, ncell)
resolution : 0.5, 0.5 (x, y)
extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
crs : +proj=longlat +datum=WGS84 +no_defs
source : memory
names : elevacion
values : 1, 36 (min, max)r_stack[["elevacion"]]
class : RasterLayer
dimensions : 6, 6, 36 (nrow, ncol, ncell)
resolution : 0.5, 0.5 (x, y)
extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
crs : +proj=longlat +datum=WGS84 +no_defs
source : memory
names : elevacion
values : 1, 36 (min, max)r_stack$elevacion
class : RasterLayer
dimensions : 6, 6, 36 (nrow, ncol, ncell)
resolution : 0.5, 0.5 (x, y)
extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
crs : +proj=longlat +datum=WGS84 +no_defs
source : memory
names : elevacion
values : 1, 36 (min, max)El operador [ también puede utilizarse para modificar los valores de un objeto raster.
# Modificación de una celda
elevacion[1, 1] = 0
# Consulta de todos los valores del raster (equivalente a values())
elevacion[]
[1] 0 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
[23] 23 24 25 26 27 28 29 30 31 32 33 34 35 36# Modificación de rangos de celdas
elevacion[1, 1:6] = 0
elevacion[2, 1:6] = 10
elevacion[3, 1:6] = 15
elevacion[4, 1:6] = 15
elevacion[5, 1:6] = 20
elevacion[6, 1:6] = 35
# Consulta de los valores
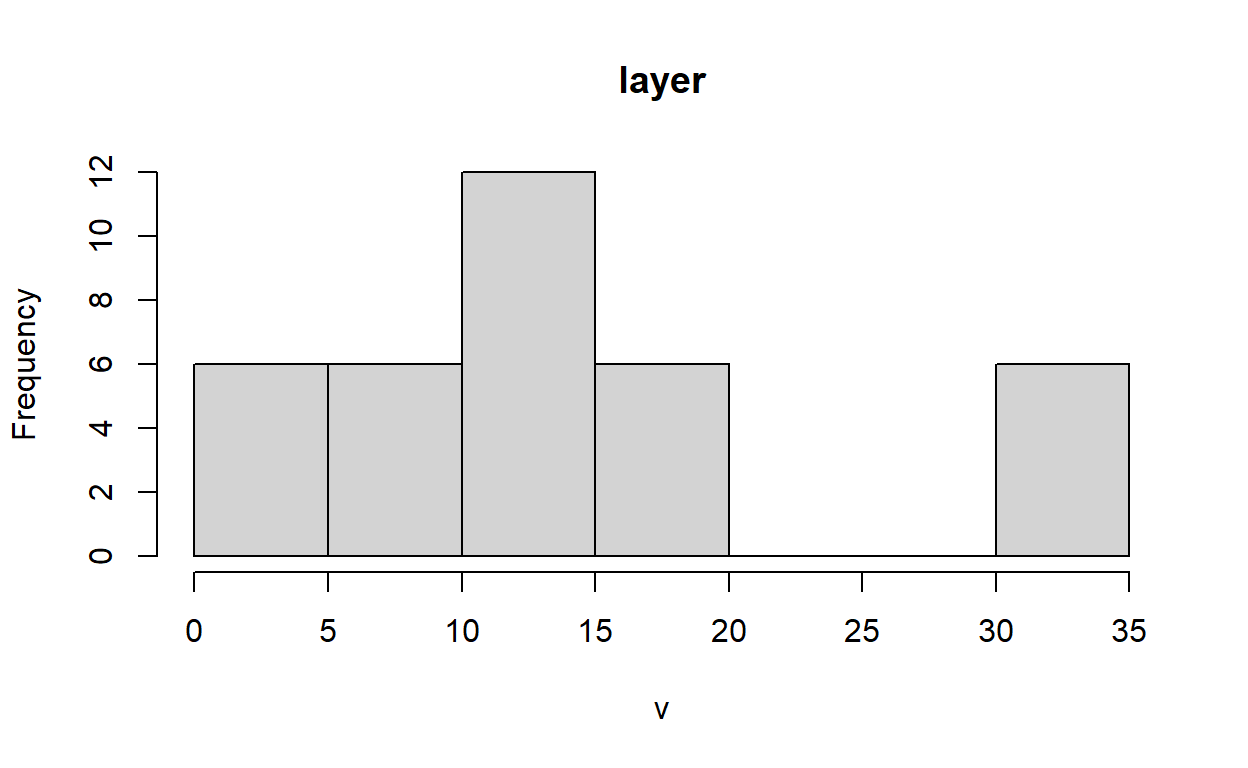
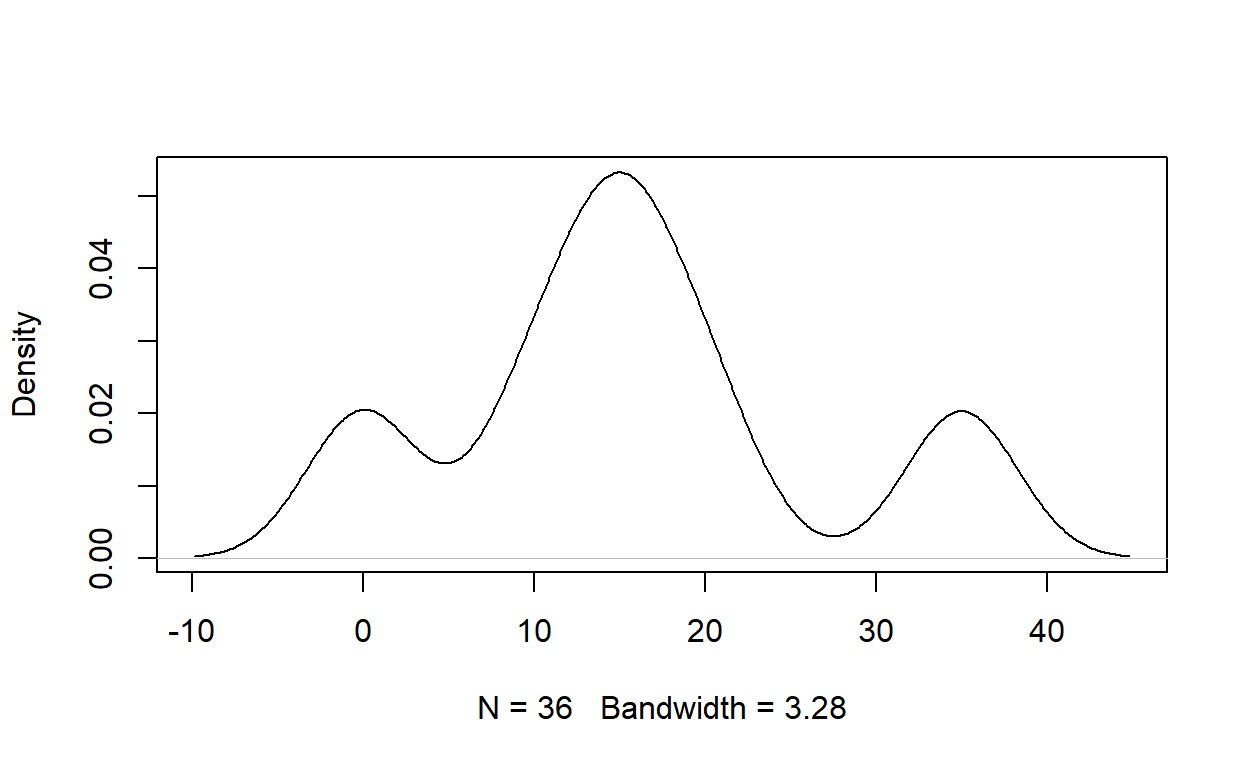
elevacion[]
[1] 0 0 0 0 0 0 10 10 10 10 10 10 15 15 15 15 15 15 15 15 15 15
[23] 15 15 20 20 20 20 20 20 35 35 35 35 35 35Resumen de información
La escritura del nombre de un objeto raster en la consola imprime información general sobre ese objeto. La función summary() proporciona algunas estadísticas descriptivas (mínimo, máximo, cuartiles, etc.). Otras estadísticas pueden ser calculadas con cellStats().
# Información general
elevacion
class : RasterLayer
dimensions : 6, 6, 36 (nrow, ncol, ncell)
resolution : 0.5, 0.5 (x, y)
extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
crs : +proj=longlat +datum=WGS84 +no_defs
source : memory
names : layer
values : 0, 35 (min, max)
# Resumen de un raster de una capa
summary(elevacion)
layer
Min. 0
1st Qu. 10
Median 15
3rd Qu. 20
Max. 35
NA's 0 layer.1 layer.2
Min. 0 1
1st Qu. 10 1
Median 15 2
3rd Qu. 20 3
Max. 35 3
NA's 0 0
# Desviación estándar
cellStats(elevacion, sd)
[1] 10.72381Las estadísticas pueden ser visualizadas con funciones como hist() y density().