# Cargar bibliotecas
library(tidyverse)
library(DT)
library(sf)
library(terra)
library(tmap)12 Operaciones con datos de atributos
12.1 Resumen
Se les llama atributos a los elementos de datos no espaciales o geométricos de un conjunto de datos geoespaciales. Estos datos pueden ser de tipos numéricos o textuales, entre otros. Un conjunto de datos vectoriales puede tener asociados varios campos de atributos, mientras que un conjunto de datos raster tiene solamente uno.
Las operaciones con atributos en datos vectoriales incluyen creación de subconjuntos, agregación y unión (join). Estas operaciones pueden ejecutarse con funciones del paquete base de R o con las de paquetes de Tidyverse, como dplyr. Por su parte, las operaciones con atributos en datos raster incluyen creación de subconjuntos y resumen de información.
12.2 Trabajo previo
12.2.1 Lecturas
Lovelace, R., Nowosad, J., & Münchow, J. (2019). Geocomputation with R (capítulo 3). CRC Press. https://geocompr.robinlovelace.net/
12.3 Carga de bibliotecas
12.4 Carga de datos
12.4.1 Cantones de Costa Rica
Este archivo proviene de un geoservicio de tipo Web Feature Service (WFS) publicado por el Instituto Geográfico Nacional (IGN). Se utiliza una versión del año 2020 (con 82 cantones), debido a que esa es la que corresponde a los datos de COVID-19 que publicó el Ministerio de Salud durante la pandemia.
Archivo GPKG de cantones de Costa Rica (del año 2020 y con geometrías simplificadas)
# Cargar datos de cantones de Costa Rica
cantones <- st_read(
"https://github.com/gf0604-procesamientodatosgeograficos/2025-i/raw/refs/heads/main/datos/ign/cantones-2020-simplificados.gpkg",
quiet = TRUE
)Código para generar el mapa y la tabla
# Mapa interactivo de cantones
# Activar el modo interactivo
tmap_mode("view")
# Definir el mapa
mapa_cantones <-
tm_basemap("OpenStreetMap.Mapnik") + # capa base OSM
tm_basemap("OpenTopoMap") + # capa base OpenTopoMap
tm_view(set.view = c(
lon = -84.19452,
lat = 9.572735,
zoom = 7
)) + # centro y zoom
tm_shape(cantones, name = "Cantones") + # capa de cantones
tm_fill(
# relleno transparente
col = NA,
alpha = 0,
id = "canton", # texto que se ve al pasar el ratón
popup.vars = c(# ventana emergente
"Código de cantón" = "cod_canton", "Cantón" = "canton")
) +
tm_borders(col = "black", lwd = 1) + # contorno negro, grosor 1
tm_scale_bar(position = c("left", "bottom")) # barra de escala
# Mostrar el mapa
mapa_cantones
# Tabla interactiva de cantones
# Definir y mostrar tabla
cantones |>
st_drop_geometry() |> # remover columna de geometrías
dplyr::select(cod_canton, canton) |> # seleccionar columnas
arrange(cod_canton) |> # ordenar filas
datatable( # crear tabla
rownames = FALSE, # omitir identificadores de filas
options = list(
dom = 'ft', # configuración de la interfaz
pageLength = 8, # cantidad de filas por página
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
)
)Mapa y tabla de cantones de Costa Rica
12.4.2 Casos positivos de COVID-19 en cantones de Costa Rica
Estos datos fueron publicados por el Ministerio de Salud de Costa Rica en https://geovision.uned.ac.cr/oges/ (a la fecha de escritura de este documento, el enlace no está funcionando). Se distribuyen en archivos CSV, incluyendo un archivo de datos generales para todo el país y varios archivos con datos por cantón. La fecha de la última actualización es 2022-05-30.
Archivo CSV de casos positivos de COVID-19 en cantones de Costa Rica
El archivo contiene una columna por cada fecha en la que se tomaron datos en el nivel de cantón. En este caso, Se carga solamente la columna de la última fecha (2022-05-30).
# Cargar datos de casos positivos de COVID-19 en cantones
covid_positivos_cantones <-
read_delim(
"https://github.com/gf0604-procesamientodatosgeograficos/2025-i/raw/refs/heads/main/datos/ministerio-salud/05_30_22_CSV_POSITIVOS.csv",
delim = ";",
locale = locale(encoding = "WINDOWS-1252"), # para desplegar correctamente acentos y otros caracteres
col_select = c("cod_provin", "provincia", "cod_canton", "canton", "30/05/2022") # 30/05/2022 contiene los datos para la última fecha disponible
)
# Remover la fila con canton == "Otros"
covid_positivos_cantones <-
covid_positivos_cantones |>
filter(canton != "Otros")
# Cambiar nombres de columnas
covid_positivos_cantones <-
covid_positivos_cantones |>
rename(positivos_20220530 = '30/05/2022')Código
# Tabla DT de casos positivos de COVID-19 en cantones
covid_positivos_cantones |>
arrange(cod_canton) |>
datatable(
rownames = FALSE,
options = list(
pageLength = 7,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
)
)Tabla de casos positivos de COVID-19 en cantones de Costa Rica
12.5 Introducción
Se les llama atributos a los elementos de datos no espaciales o geométricos de un conjunto de datos geográficos. Estos datos pueden ser de tipos numéricos o textuales, entre otros. Un conjunto de datos vectoriales puede tener asociados varios campos de atributos, mientras que un conjunto de datos raster tiene solamente uno.
12.6 Datos vectoriales
Las operaciones con atributos en datos vectoriales incluyen:
- Creación de subconjuntos (subsetting).
- Agregación (aggregation).
- Unión (joining).
Seguidamente, se explica como maneja estas operaciones el paquete sf.
12.6.1 Manejo de datos de atributos con el paquete sf
Como se mencionó en capítulos anteriores, el paquete sf define una clase, llamada sf, la cual extiende la clase data.frame del paquete base de R. Los objetos de la clase sf tienen una fila (o feature) por cada observación y una columna por cada atributo. También tienen una columna especial para almacenar las geometrías (puntos, líneas, polígonos, etc.), la cual generalmente se denomina geometry o geom (pero puede tener cualquier otro nombre). Esto permite que sf utilice métodos (i.e. funciones) de la clase data.frame, tales como plot() y summary(), entre otros.
Además de data.frame, sf es compatible con la clase tibble, la cual también puede manipularse mediante los métodos de dplyr. Esto permite un manejo tidy (i.e. ordenado, organizado) de los datos geoespaciales, de acuerdo con el enfoque de Tidyverse.
En la secciones siguientes, se explicará el manejo de datos de atributos en conjuntos de datos geoespaciales, mediante Tidyverse.
12.6.1.1 El método st_drop_geometry()
st_drop_geometry() es un método que remueve las geometrías de un objeto sf. Esto puede ser útil cuando se desea operar solamente con las variables no espaciales.
# Desplegar datos de cantones, incluyendo las geometrías
# (este es el funcionamiento por defecto)
cantones |>
dplyr::select(canton, area) |>
filter(area >= 2000)Simple feature collection with 5 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -84.86235 ymin: 8.775055 xmax: -82.55287 ymax: 10.99578
Geodetic CRS: WGS 84
canton area geom
1 Buenos Aires 2382.94 MULTIPOLYGON (((-83.32144 9...
2 Talamanca 2792.23 MULTIPOLYGON (((-82.89498 9...
3 Pococí 2408.76 MULTIPOLYGON (((-83.6793 10...
4 San Carlos 3352.31 MULTIPOLYGON (((-84.37648 1...
5 Sarapiquí 2144.38 MULTIPOLYGON (((-84.16126 1...# Desplegar datos de cantones, removiendo las geometrías con st_drop_geometry()
cantones |>
st_drop_geometry() |>
dplyr::select(canton, area) |>
filter(area >= 2000) canton area
1 Buenos Aires 2382.94
2 Talamanca 2792.23
3 Pococí 2408.76
4 San Carlos 3352.31
5 Sarapiquí 2144.38Como puede verse, la columna de geometrías se incluye como resultado de cualquier operación, a menos que se remueva explícitamente.
12.6.1.2 Creación de subconjuntos (filtrado)
Frecuentemente, es necesario extrer subconjuntos del conjunto de datos original, para facilidad de manejo y para atender requerimientos específicos de un análisis.
El paquete dplyr permite crear flujos de trabajo intuitivos y rápidos. Esto es útil, por ejemplo, cuando se trabaja con conjuntos de datos grandes (big data) y cuando se necesita integración con bases de datos. Los principales métodos de dplyr para creación de subconjuntos son select(), slice() y filter().
12.6.1.2.1 El método select()
select() permite seleccionar y renombrar columnas de un conjunto de datos.
# Seleccionar las columnas canton, area (renombrada a area_km2) y provincia
cantones |>
head(10) |> # mostrar solo las 10 primeras filas
st_drop_geometry() |> # remover la columna de geometrías
dplyr::select(canton, area_km2 = area, provincia) canton area_km2 provincia
1 Corredores 623.61 Puntarenas
2 Golfito 1753.42 Puntarenas
3 Coto Brus 944.24 Puntarenas
4 Osa 1932.03 Puntarenas
5 Buenos Aires 2382.94 Puntarenas
6 Pérez Zeledón 1901.08 San José
7 Quepos 557.85 Puntarenas
8 Talamanca 2792.23 Limón
9 Parrita 483.22 Puntarenas
10 Tarrazú 291.27 San José12.6.1.2.2 El método slice()
slice() crea un subconjunto con base en las posiciones de las filas.
# Crear un subconjunto de las filas entre la 1 y la 10
# del conjunto de datos de COVID-19
covid_positivos_cantones |>
slice(1:10)# A tibble: 10 × 5
cod_provin provincia cod_canton canton positivos_20220530
<dbl> <chr> <dbl> <chr> <dbl>
1 1 San José 112 Acosta 4104
2 1 San José 110 Alajuelita 18973
3 1 San José 106 Aserrí 10880
4 1 San José 118 Curridabat 14518
5 1 San José 103 Desamparados 43283
6 1 San José 117 Dota 834
7 1 San José 102 Escazú 15134
8 1 San José 108 Goicoechea 25497
9 1 San José 120 León Cortés Castro 1339
10 1 San José 115 Montes de Oca 998712.6.1.2.3 El método filter()
filter() filtra filas que cumplen una expresión lógica.
# Filtrar cantones de la provincia de Heredia
cantones |>
st_drop_geometry() |>
dplyr::select(provincia, canton) |>
filter(provincia == "Heredia") provincia canton
1 Heredia Santo Domingo
2 Heredia Belén
3 Heredia San Pablo
4 Heredia Heredia
5 Heredia Flores
6 Heredia San Rafael
7 Heredia Barva
8 Heredia San Isidro
9 Heredia Santa Bárbara
10 Heredia Sarapiquí12.6.1.3 Agregación
Las operaciones de agregación realizan cálculos (ej. sumas, promedios, mínimos, máximos) a partir de la agrupaciones de datos. En Tidyverse y dplyr, las agregaciones de datos se realizan con las funciones group_by() y summarize().
12.6.1.3.1 Las funciones group_by() y summarize()
group_by() crea grupos de filas de un conjunto de datos, de acuerdo con los valores de una o varias columnas. summarize() crea columnas adicionales con cálculos para cada grupo, tales como promedios, sumas, mínimos, máximos y otros. Si summarize() se ejecuta sin group_by(), crea una única fila para todo el conjunto de datos.
Por ejemplo, en un conjunto de datos de ventas de una cadena de tiendas, se podría usar group_by() para hacer un grupo por cada ciudad en la que una o varias tiendas. Luego con summarize(), se podría crear una columna con el total de ventas para cada ciudad (i.e. para cada grupo).
Agrupación y sumarización
# Sumar áreas de cantones por provincia
cantones |>
st_drop_geometry() |>
group_by(provincia) |>
summarize(area_km2 = sum(area, na.rm = TRUE))# A tibble: 7 × 2
provincia area_km2
<chr> <dbl>
1 Alajuela 9772.
2 Cartago 3093.
3 Guanacaste 10190.
4 Heredia 2663.
5 Limón 9177.
6 Puntarenas 11299.
7 San José 4970.# Sumar áreas de todos los cantones
cantones |>
st_drop_geometry() |>
summarize(area_km2 = sum(area, na.rm = TRUE)) area_km2
1 51164# Sumar áreas y contar cantones de las 3 provincias más grandes
cantones |>
st_drop_geometry() |>
dplyr::select(area, provincia) |>
group_by(provincia) %>%
summarize(
area = sum(area, na.rm = TRUE),
cantidad_cantones = n()
) |>
arrange(desc(area)) |> # orden descendente por área
top_n(n = 3, wt = area) # se separan los primeros 3# A tibble: 3 × 3
provincia area cantidad_cantones
<chr> <dbl> <int>
1 Puntarenas 11299. 11
2 Guanacaste 10190. 11
3 Alajuela 9772. 16# Sumar casos positivos de COVID-19 por provincia
covid_positivos_cantones |>
group_by(provincia) |>
summarize(positivos_20220530 = sum(positivos_20220530, na.rm = TRUE))# A tibble: 7 × 2
provincia positivos_20220530
<chr> <dbl>
1 Alajuela 179754
2 Cartago 92933
3 Guanacaste 61470
4 Heredia 100766
5 Limón 66752
6 Puntarenas 86938
7 San José 31596912.6.1.4 Unión (join)
La unión (en inglés, join) de datos ubicados en diferentes fuentes (ej. archivos) es una tarea común en análisis de información. Este tipo de operaciones se realizan con base en columnas que son comunes en los conjuntos de datos que se desea unir.
El paquete dplyr implementa varios tipos de uniones, los cuales se ilustran en la Figura 12.1.
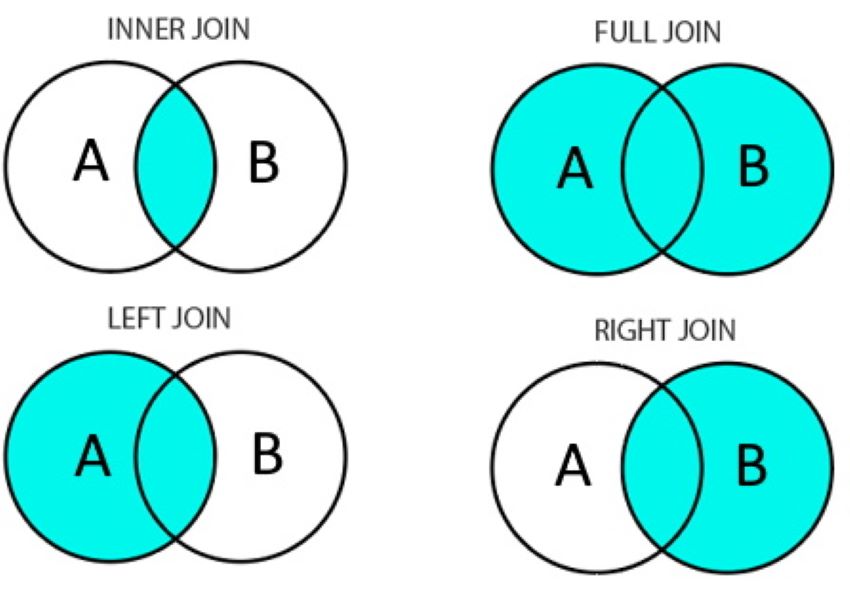
Los métodos que implementan las uniones son:
left_join(): mantiene todas las filas del conjunto de datos del lado izquierdo y les agrega las columnas del conjunto de datos del lado derecho, en las filas en las que hay coincidencia.inner_join(): incluye las filas que coinciden en ambos conjuntos de datos.right_join(): mantiene todas las filas del conjunto de datos del lado derecho y agrega las columnas del conjunto de datos del lado izquierdo, en las filas en las que hay coincidencia.full_join(): incluye todas las filas de ambos conjuntos de datos.
Todos los tipos de joins requieren de una o varias columnas que sean comunes a ambos conjuntos de datos, llamadas llaves de unión o join keys, en inglés. Esas columnas se especifican con el argumento by. Por ejemplo, by = codigo, si la columna común se llama codigo en ambos conjuntos de datos. Si tienen diferentes nombres, se utiliza un vector (ej. by = c("codigo_1" = "codigo_2"), en donde codigo_1 es el nombre de la columna en el conjunto de datos de la izquierda y codigo_2 en el de la derecha. Si hay columnas con nombres iguales en ambos conjuntos de datos, by utiliza esos nombres por defecto.
12.6.1.4.1 Ejemplo: unión de los datos geoespaciales de cantones con los datos tabulares de COVID-19
Se desea crear un mapa de coropletas de los cantones de Costa Rica, coloreado de acuerdo con la cantidad de casos positivos de COVID-19 acumulados al 2022-05-30. Para esto se necesita unir, a través de (por ejemplo) un left join, el conjunto de datos cantones (con las geometrías y otros datos de los cantones) con el conjunto de datos de covid_positivos_cantones (con la cantidad de casos positivos para cada cantón). Para ambas tablas, la llave de unión es un campo llamado cod_canton, que contiene el código de cantón asignado por el IGN. Se utiliza un left join porque se desea incluir en la unión todos las filas del conjunto de datos de cantones, ya sea que tengan o no tengan datos de COVID-19 asociados.
El siguiente bloque de código realiza el left join y almacena el resultado en un objeto sf llamado cantones_union_covid, el cual se usa como fuente de datos para generar el mapa de coropletas.
# Unir cantones con datos de COVID 19
cantones_union_covid <-
cantones |>
left_join(
dplyr::select(covid_positivos_cantones, cod_canton, positivos_20220530), # este select() es para no llevar columnas innecesarias a la unión
by = "cod_canton" # llave para realizar la unión
)Código para generar el mapa
# Mapa interactivo de casos positivos de COVID 19 en cantones
# Activar el modo interactivo
tmap_mode("view")
# Definir el mapa
mapa_cantones_covid <-
tm_basemap("OpenStreetMap.Mapnik") +
tm_view(set.view = c(
lon = -84.19452,
lat = 9.572735,
zoom = 7
)) +
tm_shape(cantones_union_covid, name = "Casos positivos de COVID") +
tm_fill(
fill = "positivos_20220530",
fill.scale = tm_scale_intervals(
style = "quantile",
values = "Reds"
),
fill.legend = tm_legend(title = "Cantidad de casos"),
id = "canton",
popup.vars = c(
"Cantón" = "canton",
"Casos" = "positivos_20220530"
)
) +
tm_borders(col = "black", lwd = 0.5) +
tm_scale_bar(position = c("left", "bottom"))
# Mostrar el mapa
mapa_cantones_covid12.6.2 Ejercicios
- Cree un mapa leaflet de coropletas de las provincias de Costa Rica, coloreado de acuerdo con la cantidad de casos positivos de COVID-19 acumulados al 2022-05-30. Se sugiere seguir los siguientes pasos:
- Cree un data frame con la suma, por provincia, de casos positivos de cantones (para realizar la agrupación, use el código de la provincia, no el nombre).
- Con un left join, una la capa de provincias (del año 2020) y el dataframe que creó en el punto a.
- Genere el mapa leaflet de coropletas con el objeto sf que creó en el punto b.
12.7 Datos raster
Las operaciones con atributos en datos raster incluyen:
- Creación de subconjuntos (subsetting).
- Resumen de información (summarizing).
Seguidamente, se explicará como maneja estas operaciones el paquete terra.
12.7.1 Manejo de datos de atributos con el paquete terra
Para ejemplificar las operaciones, se utilizarán datos de temperatura de WorldClim para Costa Rica.
# Cargar datos de temperatura
temperatura <- rast(
"https://github.com/gf0604-procesamientodatosgeograficos/2025-i/raw/refs/heads/main/datos/worldclim/temperatura.tif"
)Código para generar el mapa
# Especificar el modo interactivo
tmap_mode("view")
# Definir el mapa
mapa_temperatura <-
tm_view(set.view = c(
lon = -84.19452,
lat = 9.572735,
zoom = 7
)) +
tm_shape(temperatura, name = "Temperatura") +
tm_raster(
palette = c("lightblue", "brown", "orange", "red"),
title = "Temperatura (°C)"
) +
tm_scalebar(position = c("left", "bottom"))
# Mostrar el mapa
mapa_temperatura12.7.1.1 Resumen y sumarización de información
La escritura del nombre de un objeto SpatRaster en la consola imprime información general sobre ese objeto. La función summary() proporciona algunas estadísticas descriptivas (mínimo, máximo, cuartiles, etc.).
# Desplegar información general
temperaturaclass : SpatRaster
dimensions : 686, 545, 1 (nrow, ncol, nlyr)
resolution : 0.008333333, 0.008333333 (x, y)
extent : -87.1, -82.55833, 5.5, 11.21667 (xmin, xmax, ymin, ymax)
coord. ref. : lon/lat WGS 84 (EPSG:4326)
source : temperatura.tif
name : temperatura # Desplegar resumen
summary(temperatura) temperatura
Min. : 6.09
1st Qu.:22.00
Median :25.38
Mean :23.59
3rd Qu.:26.21
Max. :27.76
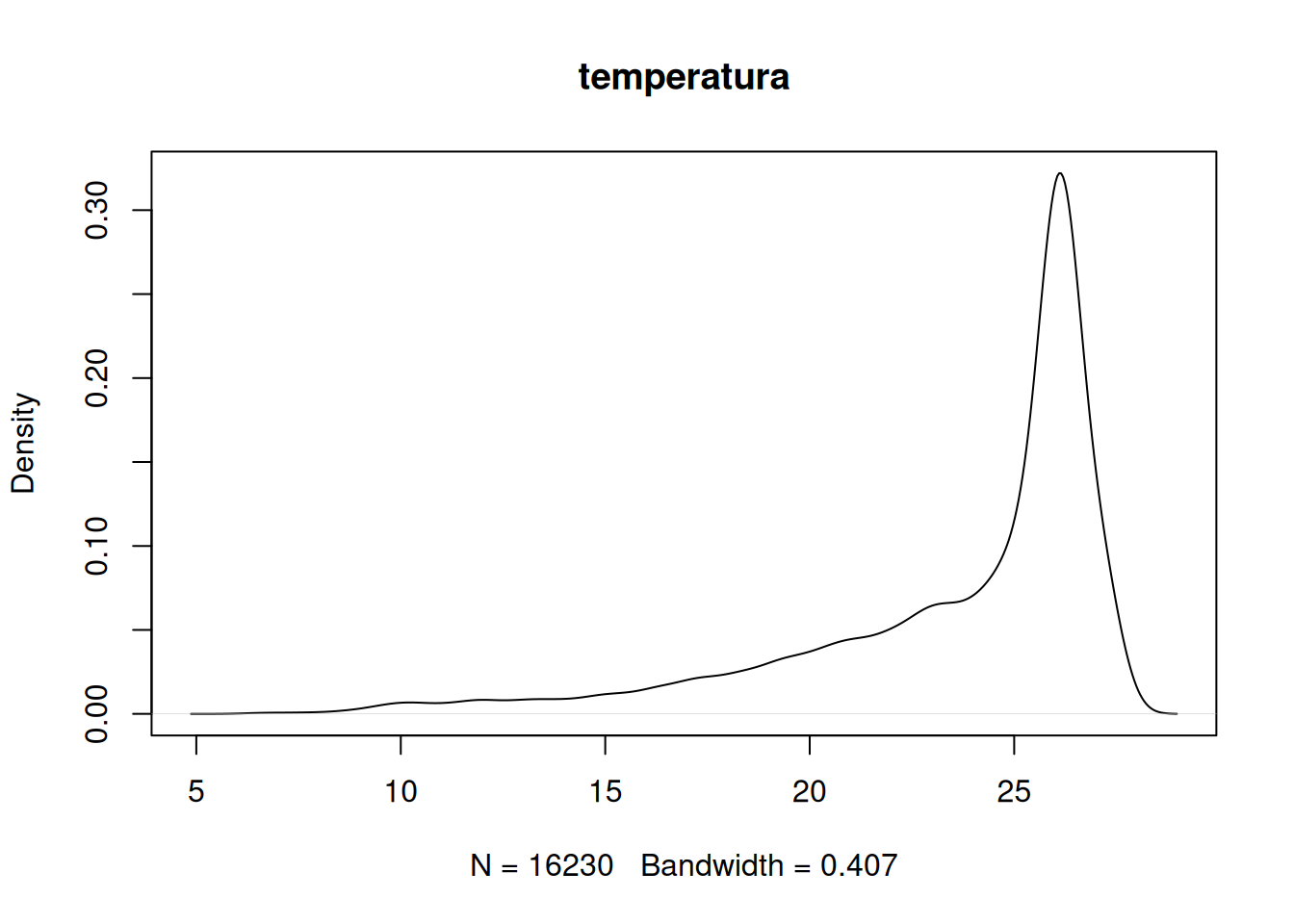
NA's :83880 Las estadísticas pueden ser visualizadas con funciones como hist() y density().
# Desplegar histograma
hist(temperatura)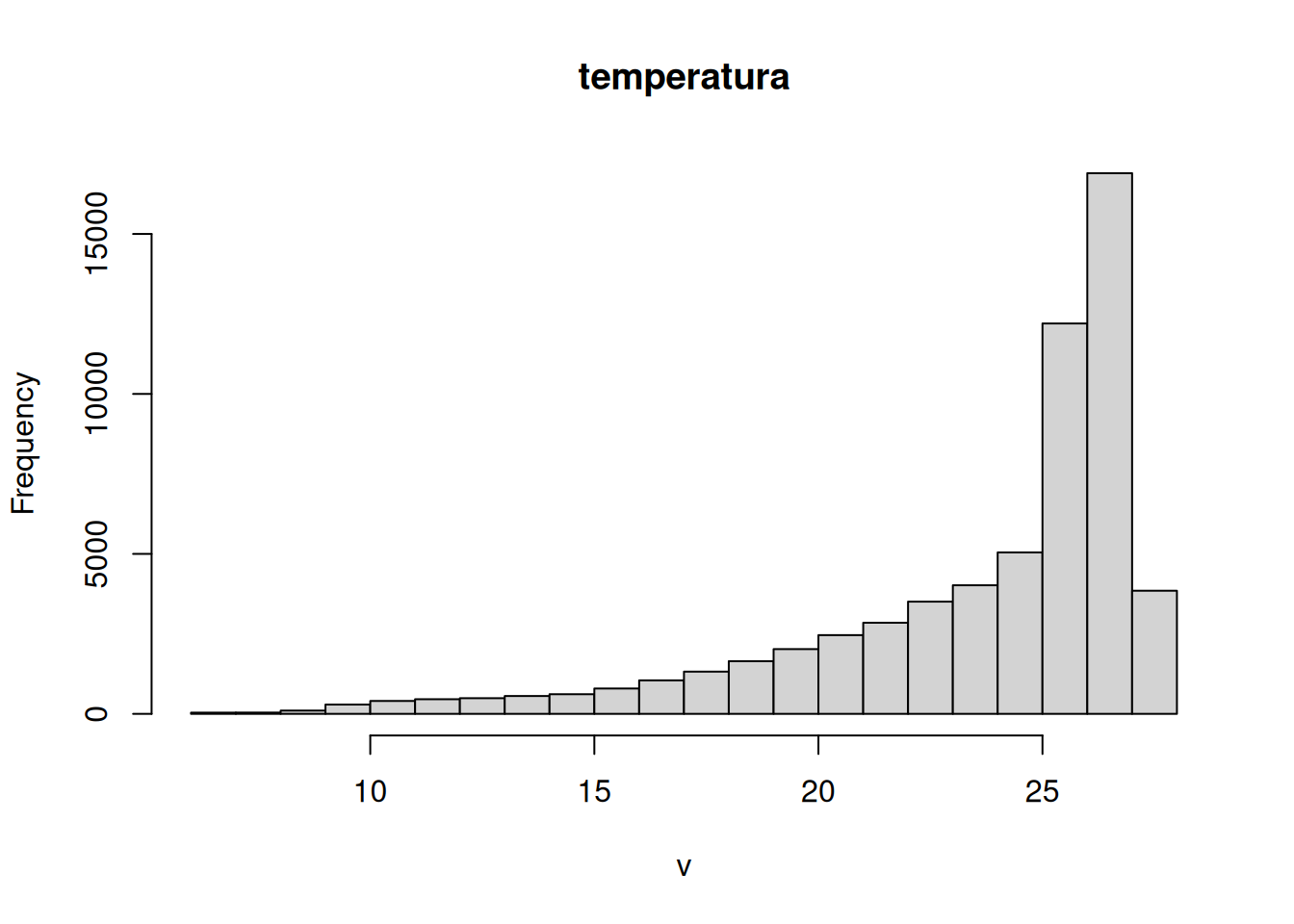
# Desplegar gráfico de densidad
density(temperatura)