14 Operaciones con datos de atributos
14.1 Resumen
Se les llama atributos a los elementos de datos no espaciales o geométricos de un conjunto de datos geoespaciales. Estos datos pueden ser de tipos numéricos o textuales, entre otros. Un conjunto de datos vectoriales puede tener asociados varios campos de atributos, mientras que un conjunto de datos raster tiene solamente uno.
Las operaciones con atributos en datos vectoriales incluyen creación de subconjuntos, agregación y cruce de datos. Estas operaciones pueden ejecutarse con funciones del paquete base de R o con las de paquetes de Tidyverse. Por su parte, las operaciones con atributos en datos raster incluyen creación de subconjuntos y resumen de información.
14.2 Trabajo previo
14.2.1 Lecturas
Lovelace, R., Nowosad, J., & Münchow, J. (2019). Geocomputation with R (capítulo 3). CRC Press. https://geocompr.robinlovelace.net/
14.3 Preparativos
14.3.1 Carga de paquetes
# Carga de paquetes
library(stringi) # manejo de hileras de texto
library(readr) # lectura de archivos CSV
library(readxl) # lectura de archivos XLS
library(dplyr) # transformación de datos
library(DT) # tablas interactivas
library(sf) # manejo de datos vectoriales
library(terra) # manejo de datos raster
library(leaflet) # mapas interactivos14.3.2 Conjuntos de datos para ejemplos
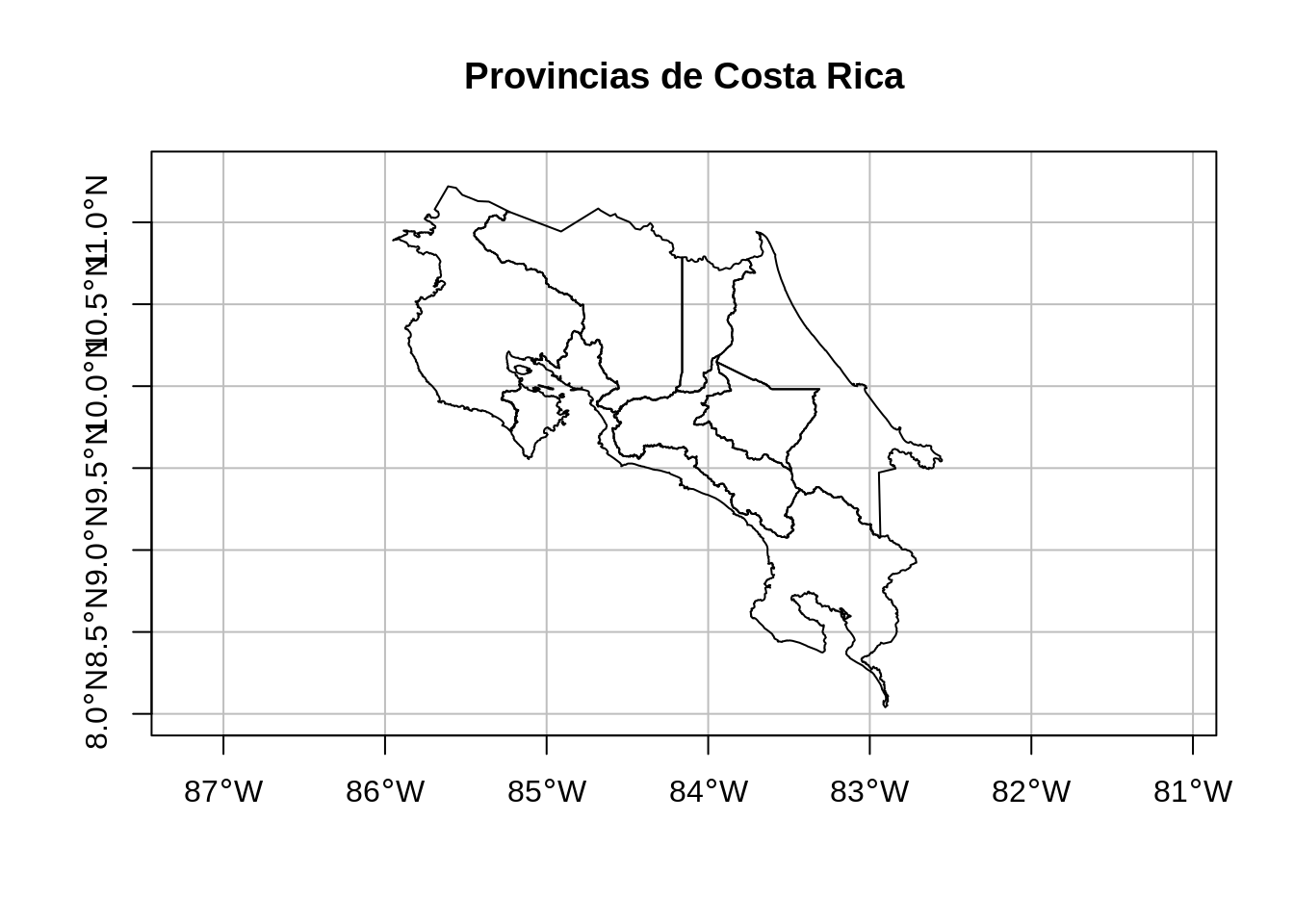
14.3.2.1 Provincias de Costa Rica
Es un archivo GeoJSON con los polígonos de las provincias de Costa Rica. Este archivo proviene de un geoservicio de tipo Web Feature Service (WFS) publicado por el Instituto Geográfico Nacional (IGN). Se transforma a WGS84 para posteriormente desplegarlo más fácilmente en leaflet.
# Lectura, transformación y visualización de datos geoespaciales de provincias
# Lectura
provincias <-
st_read(
dsn = "datos/ign/delimitacion-territorial-administrativa/provincias.geojson",
quiet = TRUE
) %>%
st_transform(4326) # transformación a WGS84
# Transformación
provincias <-
provincias %>%
st_transform(5367) %>%
st_simplify(dTolerance = 100) %>% # simplificación de geometrías
st_transform(4326)
# Visualización en un mapa
plot(
provincias$geometry,
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
main = "Provincias de Costa Rica",
axes = TRUE,
graticule = TRUE
)
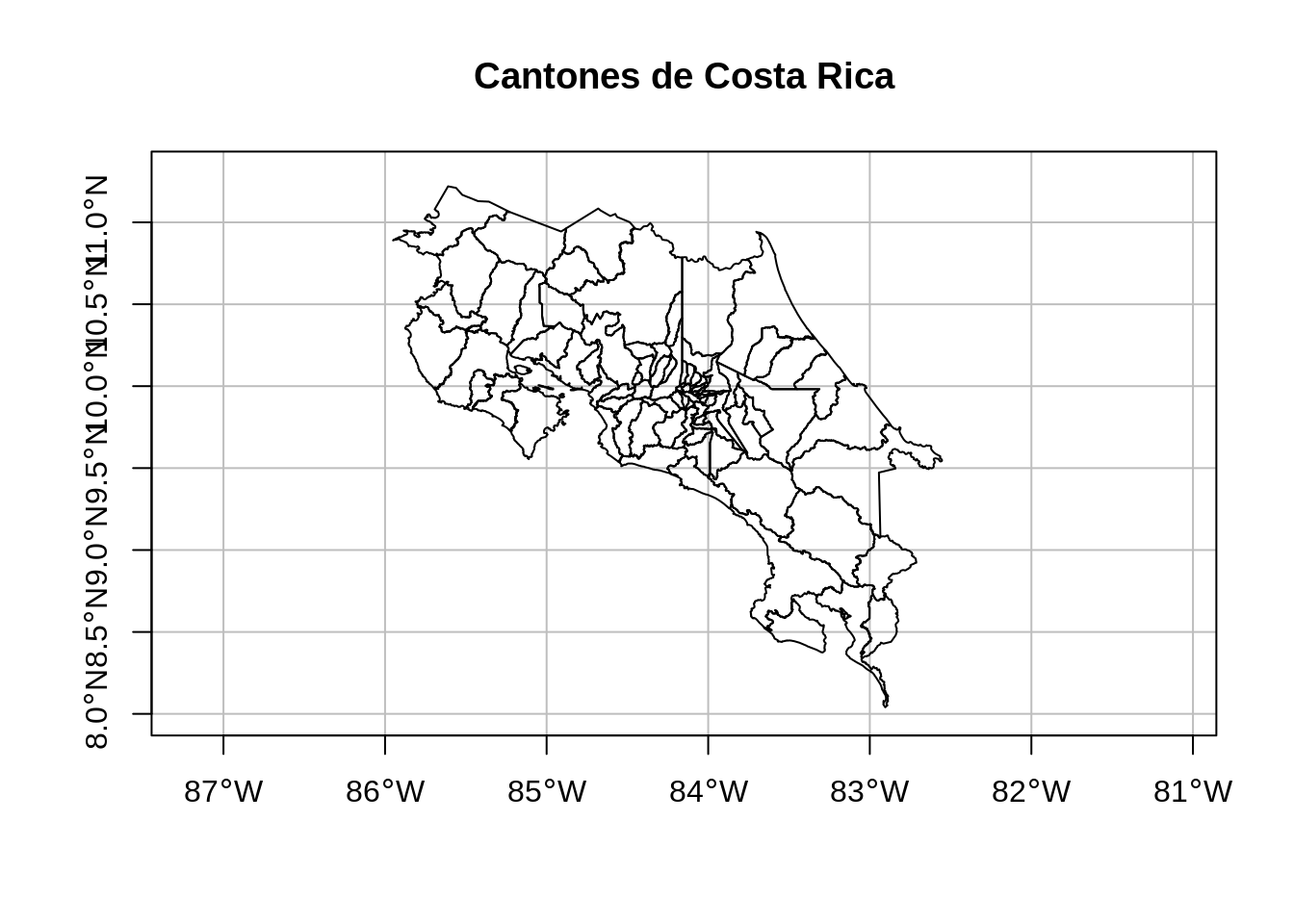
14.3.2.2 Cantones de Costa Rica
Es un archivo GeoJSON con los polígonos de los cantones de Costa Rica. Este archivo proviene de un geoservicio de tipo Web Feature Service (WFS) publicado por el Instituto Geográfico Nacional (IGN). Se transforma a WGS84 para posteriormente desplegarlo más fácilmente en leaflet.
# Lectura, transformación y visualización de datos geoespaciales de cantones
# Lectura
cantones <-
st_read(
dsn = "datos/ign/delimitacion-territorial-administrativa/cantones.geojson",
quiet = TRUE
) %>%
st_transform(4326) # transformación a WGS84
# Transformación
cantones <-
cantones %>%
st_transform(5367) %>%
st_simplify(dTolerance = 100) %>% # simplificación de geometrías
st_transform(4326)
# Visualización en un mapa
plot(
cantones$geometry,
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
main = "Cantones de Costa Rica",
axes = TRUE,
graticule = TRUE
)
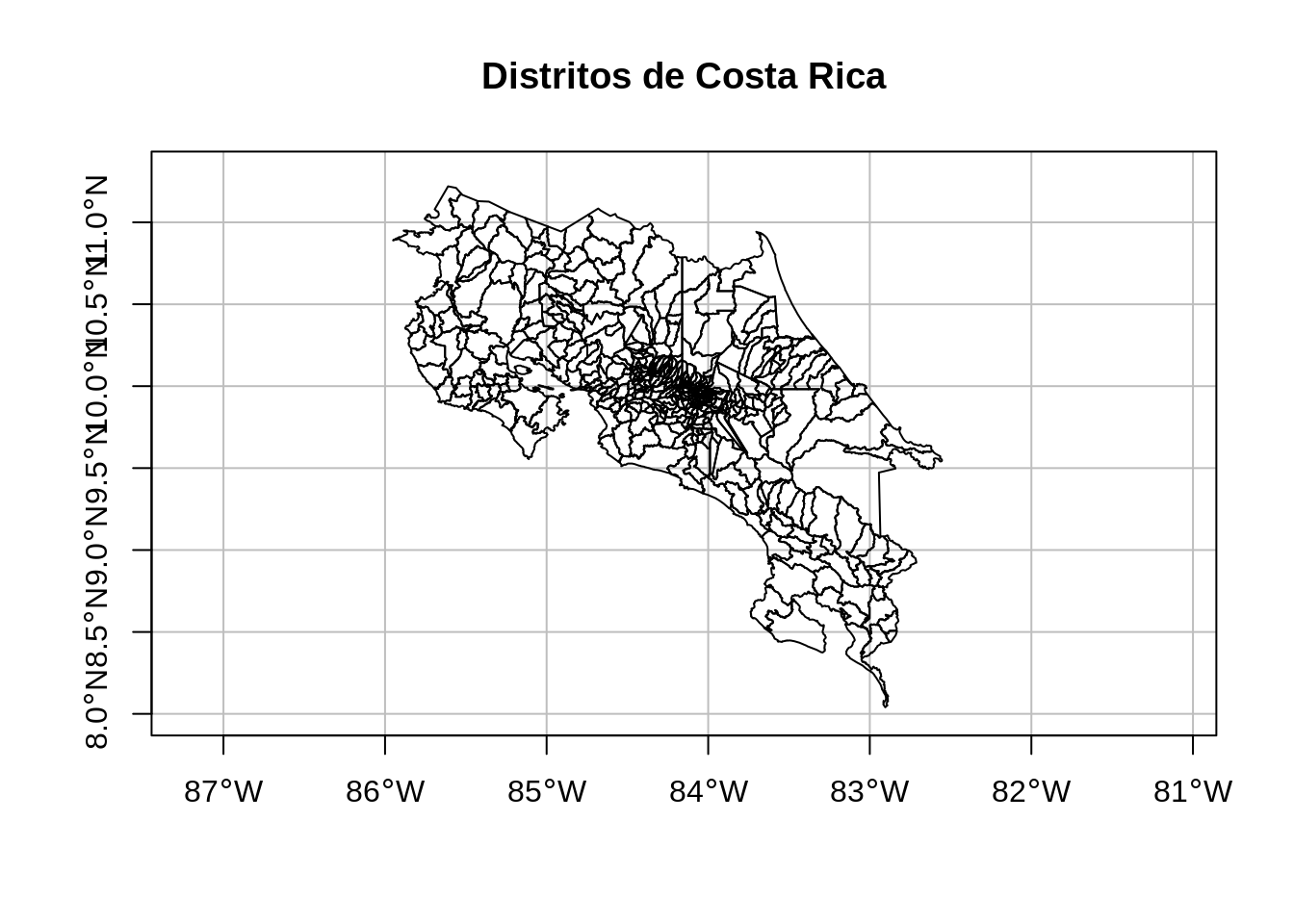
14.3.2.3 Distritos de Costa Rica
Es un archivo GeoJSON con los polígonos de los distritos de Costa Rica. Este archivo proviene de un geoservicio de tipo Web Feature Service (WFS) publicado por el Instituto Geográfico Nacional (IGN). Se transforma a WGS84 para posteriormente desplegarlo más fácilmente en leaflet.
# Lectura, transformación y visualización de datos geoespaciales de distritos
# Lectura
distritos <-
st_read(
dsn = "datos/ign/delimitacion-territorial-administrativa/distritos.geojson",
quiet = TRUE
) %>%
st_transform(4326) # transformación a WGS84
# Transformación
distritos <-
distritos %>%
st_transform(5367) %>%
st_simplify(dTolerance = 100) %>% # simplificación de geometrías
st_transform(4326)
# Visualización en un mapa
plot(
distritos$geometry,
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
main = "Distritos de Costa Rica",
axes = TRUE,
graticule = TRUE
)
14.3.2.4 Casos positivos acumulados de covid en cantones de Costa Rica
Es un archivo CSV con el acumulado de casos positivos de covid-19 en cada cantón. Es publicado regularmente por el Ministerio de Salud en el sitio web Situación Nacional COVID-19.
# Lectura, transformación y visualización de casos positivos acumulados de covid-19 en cantones de Costa Rica
# Lectura
covid_positivos <-
read_delim(file = "datos/ministerio-salud/covid/05_30_22_CSV_POSITIVOS.csv",
locale = locale(encoding = "WINDOWS-1252"), # para desplegar correctamente acentos y otros caracteres
col_select = c("cod_canton", "canton", "30/05/2022"))
# Transformación
covid_positivos <-
covid_positivos %>%
rename(positivos = '30/05/2022') # renombramiento de columna
# Visualización en una tabla
covid_positivos %>%
arrange(desc(positivos)) %>%
datatable(options = list(
pageLength = 10,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))14.3.2.5 Delitos ocurridos en Costa Rica en el año 2021
Es un archivo XLS con registros de delitos. Es publicado regularmente por el Organismo de Investigación Judicial (OIJ) en el sitio web Datos abiertos del OIJ.
# Lectura, transformación y visualización de delitos
# Lectura
delitos <-
read_xls(path = "datos/oij/estadisticas-policiales/estadisticaspoliciales2021.xls")
# Visualización en una tabla
delitos %>%
select(Delito, Fecha, Victima, Provincia, Canton, Distrito) %>%
datatable(options = list(
pageLength = 10,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))14.4 Introducción
Se les llama atributos a los elementos de datos no espaciales o geométricos de un conjunto de datos geográficos. Estos datos pueden ser de tipos numéricos o textuales, entre otros. Un conjunto de datos vectoriales puede tener asociados varios campos de atributos, mientras que un conjunto de datos raster tiene solamente uno.
14.5 Datos vectoriales
Las operaciones con atributos en datos vectoriales incluyen:
- Creación de subconjuntos (subsetting).
- Agregación de datos (aggregation).
- Unión de datos (joining).
Seguidamente, se explicará como maneja estas operaciones el paquete sf.
14.6 Manejo de datos de atributos con el paquete sf
Como se mencionó en capítulos anteriores, el paquete sf define una clase, llamada sf, la cual extiende la clase data.frame del paquete base de R. Los objetos de la clase sf tienen una fila (o feature) por cada observación y una columna por cada atributo. También tienen una columna especial para almacenar las geometrías (puntos, líneas, polígonos, etc.), la cual generalmente se denomina geometry o geom. Esto permite que sf utilice métodos (i.e. funciones) de la clase data.frame, tales como plot() y summary(), entre otros.
Además de data.frame, sf es compatible con clases como las del paquete tibble, las cuales pueden manipularse mediante los métodos de dplyr. Esto que permite un manejo tidy (i.e. ordenado, organizado) de los datos geoespaciales, de acuerdo con el enfoque de Tidyverse.
En la secciones siguientes, se explicará el manejo de datos de atributos tanto mediante funciones y operaciones del paquete base de R, como mediante Tidyverse.
14.6.1 Funciones básicas para manejo de data frames y objetos sf
Las siguientes son algunas de las funciones disponibles para obtener información básica de un objeto sf.
# Funciones básicas para manejo de objetos tipo data.frame y sf
# Clase de cantones
class(cantones)
#> [1] "sf" "data.frame"
# Dimensiones (cantidad de filas y de columnas)
dim(cantones)
#> [1] 82 11
# Cantidad de filas (i.e. observaciones)
nrow(cantones)
#> [1] 82
# Cantidad de columnas (i.e. variables)
ncol(cantones)
#> [1] 11
# Nombres de las columnas
names(cantones)
#> [1] "gml_id" "gmlid" "cod_catalo" "cod_canton"
#> [5] "canton" "ori_toponi" "area" "cod_provin"
#> [9] "provincia" "version" "geometry"
# Estructura del conjunto de datos
glimpse(cantones)
#> Rows: 82
#> Columns: 11
#> $ gml_id <chr> "limitecantonal_5k.1", "limitecantonal_…
#> $ gmlid <chr> "limitecantonal_5k.1", "limitecantonal_…
#> $ cod_catalo <chr> "160104", "160104", "160104", "160104",…
#> $ cod_canton <int> 610, 607, 608, 605, 603, 119, 606, 704,…
#> $ canton <chr> "Corredores", "Golfito", "Coto Brus", "…
#> $ ori_toponi <chr> "Tiene su origen en el topónimo del río…
#> $ area <dbl> 623.61, 1752.75, 944.24, 1932.70, 2382.…
#> $ cod_provin <int> 6, 6, 6, 6, 6, 1, 6, 7, 6, 1, 1, 6, 1, …
#> $ provincia <chr> "Puntarenas", "Puntarenas", "Puntarenas…
#> $ version <chr> "20201222", "20201222", "20201222", "20…
#> $ geometry <GEOMETRY [°]> POLYGON ((-82.94161 8.42039...…La función st_drop_geometry() remueve la columna de geometría de un objeto sf. Puede ser útil cuando, por ejemplo, solo se necesita trabajar con los atributos o cuando la columna con la geometría consume demasiados recursos del computador.
# Ejemplos de uso de st_drop_geometry()
# Remoción de la columna de geometría
cantones_df <- st_drop_geometry(cantones)
# Nombres de las columnas (nótese que ya no está la columna de geometría)
names(cantones_df)
#> [1] "gml_id" "gmlid" "cod_catalo" "cod_canton"
#> [5] "canton" "ori_toponi" "area" "cod_provin"
#> [9] "provincia" "version"
# Clase de df_cantones (nótese como no se muestra ya la clase sf)
class(cantones_df)
#> [1] "data.frame"
# Tamaño del conjunto de datos original (tipo sf)
print(object.size(cantones), units="Kb")
#> 402.1 Kb
# Tamaño del conjunto de datos sin geometrías (tipo data.frame)
print(object.size(cantones_df), units="Kb")
#> 42.5 KbPara algunas operaciones, también es posible ocultar la columna de geometría de un conjunto de datos (sin borrarla) mediante el argumento drop = TRUE.
# Ejemplos de uso del argumento drop
# Sin drop = TRUE
cantones[1:10, c("canton", "area")]
#> Simple feature collection with 10 features and 2 fields
#> Geometry type: GEOMETRY
#> Dimension: XY
#> Bounding box: xmin: -84.55536 ymin: 8.040247 xmax: -82.55287 ymax: 9.767524
#> Geodetic CRS: WGS 84
#> canton area geometry
#> 1 Corredores 623.61 POLYGON ((-82.94161 8.42039...
#> 2 Golfito 1752.75 MULTIPOLYGON (((-83.32383 8...
#> 3 Coto Brus 944.24 POLYGON ((-82.90501 8.77424...
#> 4 Osa 1932.70 POLYGON ((-83.83946 9.25534...
#> 5 Buenos Aires 2382.94 POLYGON ((-83.32101 9.38409...
#> 6 Pérez Zeledón 1901.08 POLYGON ((-83.77329 9.59825...
#> 7 Quepos 557.85 POLYGON ((-84.17009 9.42779...
#> 8 Talamanca 2792.23 POLYGON ((-82.89452 9.76752...
#> 9 Parrita 483.22 POLYGON ((-84.30298 9.64968...
#> 10 Tarrazú 291.27 POLYGON ((-83.98178 9.71801...
# Con drop = TRUE
cantones[1:10, c("canton", "area"), drop = TRUE]
#> canton area
#> 1 Corredores 623.61
#> 2 Golfito 1752.75
#> 3 Coto Brus 944.24
#> 4 Osa 1932.70
#> 5 Buenos Aires 2382.94
#> 6 Pérez Zeledón 1901.08
#> 7 Quepos 557.85
#> 8 Talamanca 2792.23
#> 9 Parrita 483.22
#> 10 Tarrazú 291.2714.6.2 Creación de subconjuntos
Frecuentemente, es necesario extrer subconjuntos del conjunto de datos original, para facilidad de manejo y para atender requerimientos específicos de un análisis. En esta sección, se explican las diferentes opciones para creación de subconjuntos, tanto con el paquete base de R como con dplyr. En resumen, estas son las opciones:
- Con el paquete base:
- La notación de
[]y$ - La función
subset()
- La notación de
- Con el paquete
dplyr:
14.6.2.1 Notaciones y funciones del paquete base
14.6.2.1.1 La notación de [] y $
La notación de paréntesis cuadrados ([]) y el signo de dólar ($) permite crear subconjuntos con base en la posición de filas y de columnas, por medio de nombres de columnas y a través de la especificación de condiciones (i.e. expresiones lógicas).
# Ejemplos de uso de la notación []
# Subconjunto especificado por posiciones de filas
cantones[1:10, ]
# Subconjunto especificado por posiciones de columnas
cantones[, 8:10]
# Subconjunto especificado por nombres de columnas
cantones[, c("canton", "area", "provincia")]Especificación mediante una condición (i.e. expresión lógica):
# Ejemplos de uso de la notación $
# Cantones de la provincia de Cartago
cantones[cantones$provincia == "Cartago", c("canton", "provincia"), drop = TRUE]
#> canton provincia
#> 19 El Guarco Cartago
#> 20 Cartago Cartago
#> 22 Paraíso Cartago
#> 23 Jiménez Cartago
#> 24 Turrialba Cartago
#> 26 Oreamuno Cartago
#> 29 La Unión Cartago
#> 34 Alvarado Cartago14.6.2.1.2 La función subset()
La función subset() también retorna un subconjunto cuyos registros cumplen una condición.
# Ejemplos de uso de subset()
# Cantones con área >= 2000 km2
subset(cantones[, c("canton", "area"), drop = TRUE],
area >= 2000)
#> canton area
#> 5 Buenos Aires 2382.94
#> 8 Talamanca 2792.23
#> 70 Pococí 2408.76
#> 71 San Carlos 3352.33
#> 74 Sarapiquí 2144.38Los operadores lógicos y de comparación que pueden utilizarse en las condiciones de la función subset(), y en expresiones lógicas en general, se listan en la siguiente tabla:
| Operador | Descripción |
|---|---|
| == | igual a |
| != | distinto de |
| >, < | mayor que, menor que |
| >=, <= | mayor o igual que, menor o igual que |
| &, |, ! | Operadores lógicos: y, o, no |
14.6.2.2 Métodos del paquete dplyr
Las funciones del paquete base de R son confiables y ampliamente usadas. Sin embargo, el enfoque más moderno de dplyr permite flujos de trabajo más intuitivos y es más rápido, debido a que se apoya en código escrito en el lenguaje C++. Esto es útil, por ejemplo, cuando se trabaja con conjuntos de datos grandes (big data) y cuando se necesita integración con bases de datos. Los principales métodos de dplyr para creación de subconjuntos son select(), slice() y filter().
14.6.2.2.1 El método select()
dplyr::select() permite seleccionar y renombrar columnas de un conjunto de datos.
# Ejemplos de uso de dplyr::select()
# Selección de columnas
cantones %>%
dplyr::select(canton, provincia) # se especifica el nombre del paquete para evitar un conflicto con raster::select
#> Simple feature collection with 82 features and 2 fields
#> Geometry type: GEOMETRY
#> Dimension: XY
#> Bounding box: xmin: -87.09455 ymin: 5.498567 xmax: -82.55287 ymax: 11.21964
#> Geodetic CRS: WGS 84
#> First 10 features:
#> canton provincia geometry
#> 1 Corredores Puntarenas POLYGON ((-82.94161 8.42039...
#> 2 Golfito Puntarenas MULTIPOLYGON (((-83.32383 8...
#> 3 Coto Brus Puntarenas POLYGON ((-82.90501 8.77424...
#> 4 Osa Puntarenas POLYGON ((-83.83946 9.25534...
#> 5 Buenos Aires Puntarenas POLYGON ((-83.32101 9.38409...
#> 6 Pérez Zeledón San José POLYGON ((-83.77329 9.59825...
#> 7 Quepos Puntarenas POLYGON ((-84.17009 9.42779...
#> 8 Talamanca Limón POLYGON ((-82.89452 9.76752...
#> 9 Parrita Puntarenas POLYGON ((-84.30298 9.64968...
#> 10 Tarrazú San José POLYGON ((-83.98178 9.71801...
# Selección y cambio de nombre de columnas
cantones %>%
dplyr::select(canton, area_km2 = area, provincia)
#> Simple feature collection with 82 features and 3 fields
#> Geometry type: GEOMETRY
#> Dimension: XY
#> Bounding box: xmin: -87.09455 ymin: 5.498567 xmax: -82.55287 ymax: 11.21964
#> Geodetic CRS: WGS 84
#> First 10 features:
#> canton area_km2 provincia
#> 1 Corredores 623.61 Puntarenas
#> 2 Golfito 1752.75 Puntarenas
#> 3 Coto Brus 944.24 Puntarenas
#> 4 Osa 1932.70 Puntarenas
#> 5 Buenos Aires 2382.94 Puntarenas
#> 6 Pérez Zeledón 1901.08 San José
#> 7 Quepos 557.85 Puntarenas
#> 8 Talamanca 2792.23 Limón
#> 9 Parrita 483.22 Puntarenas
#> 10 Tarrazú 291.27 San José
#> geometry
#> 1 POLYGON ((-82.94161 8.42039...
#> 2 MULTIPOLYGON (((-83.32383 8...
#> 3 POLYGON ((-82.90501 8.77424...
#> 4 POLYGON ((-83.83946 9.25534...
#> 5 POLYGON ((-83.32101 9.38409...
#> 6 POLYGON ((-83.77329 9.59825...
#> 7 POLYGON ((-84.17009 9.42779...
#> 8 POLYGON ((-82.89452 9.76752...
#> 9 POLYGON ((-84.30298 9.64968...
#> 10 POLYGON ((-83.98178 9.71801...14.6.2.2.2 El método slice()
slice() es el equivalente de select() para filas. Crea un subconjunto con base en las posiciones de las filas.
14.6.2.2.3 El método filter()
filter() es el equivalente en dplyr de la función subset() del paquete base. Retorna los registros que cumplen con una condición.
# Androides de "La Guerra de las Galaxias"
starwars %>%
filter(species == "Droid")
#> # A tibble: 6 × 14
#> name height mass hair_color skin_color eye_color
#> <chr> <int> <dbl> <chr> <chr> <chr>
#> 1 C-3PO 167 75 <NA> gold yellow
#> 2 R2-D2 96 32 <NA> white, blue red
#> 3 R5-D4 97 32 <NA> white, red red
#> 4 IG-88 200 140 none metal red
#> 5 R4-P17 96 NA none silver, red red, blue
#> 6 BB8 NA NA none none black
#> # … with 8 more variables: birth_year <dbl>, sex <chr>,
#> # gender <chr>, homeworld <chr>, species <chr>,
#> # films <list>, vehicles <list>, starships <list>14.6.2.2.4 El operador pipe (%>%)
Los métodos del paquete dplyr (y otros) suelen ser utilizados conjuntamente con el operador pipe (%>%), el cual posibilita el “encadenamiento” (chaining) de funciones: la salida de la función previa se convierte en el primer argumento de la siguiente función. En el siguiente ejemplo, el conjunto de datos starwars se pasa como entrada al método filter(), para filtrar los personajes humanos. Seguidamente, el resultado se pasa a select(), para seleccionar las columnas name, homeworld y species. Finalmente, slice() reduce el resultado a las 10 primeras filas.
# Encadenamiento de funciones mediante pipes (%>%)
starwars %>%
filter(species == "Human") %>%
dplyr::select(name, homeworld, species) %>%
slice(1:10)
#> # A tibble: 10 × 3
#> name homeworld species
#> <chr> <chr> <chr>
#> 1 Luke Skywalker Tatooine Human
#> 2 Darth Vader Tatooine Human
#> 3 Leia Organa Alderaan Human
#> 4 Owen Lars Tatooine Human
#> 5 Beru Whitesun lars Tatooine Human
#> 6 Biggs Darklighter Tatooine Human
#> 7 Obi-Wan Kenobi Stewjon Human
#> 8 Anakin Skywalker Tatooine Human
#> 9 Wilhuff Tarkin Eriadu Human
#> 10 Han Solo Corellia HumanUna alternativa al uso de pipes es el “anidamiento” (nesting) de las funciones:
# Anidamiento de funciones
slice(
dplyr::select(
filter(
starwars,
species=="Human"
),
name, homeworld, species
),
1:10
)
#> # A tibble: 10 × 3
#> name homeworld species
#> <chr> <chr> <chr>
#> 1 Luke Skywalker Tatooine Human
#> 2 Darth Vader Tatooine Human
#> 3 Leia Organa Alderaan Human
#> 4 Owen Lars Tatooine Human
#> 5 Beru Whitesun lars Tatooine Human
#> 6 Biggs Darklighter Tatooine Human
#> 7 Obi-Wan Kenobi Stewjon Human
#> 8 Anakin Skywalker Tatooine Human
#> 9 Wilhuff Tarkin Eriadu Human
#> 10 Han Solo Corellia HumanEjercicio: mediante las funciones select() y filter() de dplyr, cree un nuevo objeto sf que contenga los cantones de Puntarenas y Guanacaste con área mayor o igual a 2000 km2. Incluya las columnas de provincia, cantón y área.
14.6.3 Agregación de datos
Las operaciones de agregación realizan cálculos (suma, promedio, etc.) a partir de la agrupación de valores de variables. En esta sección, se explican funciones de agregación contenidas en los paquetes stats, sf y dplyr, las cuales son:
- Del paquete stats:
- La función
aggregate()
- La función
- Del paquete sf:
- El método
aggregate()
- El método
- Del paquete dplyr:
- El método
summarize()
- El método
14.6.3.1 La función aggregate() de stats
La función aggregate() del paquete stats aplica una función de agregación (ej. suma, promedio, mínimo, máximo) sobre una columna. El resultado es un objeto de tipo data.frame.
# Ejemplos de uso de stats::agregate()
# Suma de áreas de cantones por provincia
aggregate(
data = cantones,
area ~ provincia,
FUN = sum,
na.rm = TRUE
)
#> provincia area
#> 1 Alajuela 9772.26
#> 2 Cartago 3093.23
#> 3 Guanacaste 10196.30
#> 4 Heredia 2663.45
#> 5 Limón 9176.97
#> 6 Puntarenas 11298.51
#> 7 San José 4969.7314.6.3.2 El método aggregate() de sf
aggregate() es una función genérica, lo que significa que puede comportarse de manera diferente, dependiendo de los valores de entrada. El paquete sf también provee una versión de aggregate(), la cual se activa cuando recibe un objeto sf`` y se usa el argumentoby. El resultado es un objeto de tiposf`.
# Ejemplos de uso de sf::agregate()
# Suma de áreas de cantones por provincia
aggregate(
cantones["area"],
by = list(cantones$provincia),
FUN = sum,
na.rm = TRUE
)
#> Simple feature collection with 7 features and 2 fields
#> Attribute-geometry relationship: 0 constant, 1 aggregate, 1 identity
#> Geometry type: GEOMETRY
#> Dimension: XY
#> Bounding box: xmin: -87.09455 ymin: 5.498567 xmax: -82.55287 ymax: 11.21964
#> Geodetic CRS: WGS 84
#> Group.1 area geometry
#> 1 Alajuela 9772.26 POLYGON ((-84.46238 9.92400...
#> 2 Cartago 3093.23 POLYGON ((-83.81609 10.0836...
#> 3 Guanacaste 10196.30 MULTIPOLYGON (((-85.45258 9...
#> 4 Heredia 2663.45 POLYGON ((-84.10945 9.96124...
#> 5 Limón 9176.97 POLYGON ((-82.85462 9.74693...
#> 6 Puntarenas 11298.51 MULTIPOLYGON (((-87.03717 5...
#> 7 San José 4969.73 POLYGON ((-84.15748 9.62847...
14.6.3.3 El método summarise() de dplyr
summarise() es el equivalente de aggregate() en el paquete dplyr. Suele utilizarse conjuntamente con group_by(), que especifica la variable a agrupar.
# Ejemplos de uso de de summarise()
# Suma de áreas de cantones por provincia
cantones %>%
group_by(provincia) %>%
summarise(area_km2 = sum(area, na.rm = TRUE))
#> Simple feature collection with 7 features and 2 fields
#> Geometry type: GEOMETRY
#> Dimension: XY
#> Bounding box: xmin: -87.09455 ymin: 5.498567 xmax: -82.55287 ymax: 11.21964
#> Geodetic CRS: WGS 84
#> # A tibble: 7 × 3
#> provincia area_km2 geometry
#> <chr> <dbl> <GEOMETRY [°]>
#> 1 Alajuela 9772. POLYGON ((-85.2428 11.06558, -85.2432…
#> 2 Cartago 3093. POLYGON ((-83.99753 9.876007, -83.999…
#> 3 Guanacaste 10196. MULTIPOLYGON (((-85.08991 10.16697, -…
#> 4 Heredia 2663. POLYGON ((-84.16108 10.29794, -84.161…
#> 5 Limón 9177. POLYGON ((-83.6764 10.90648, -83.6762…
#> 6 Puntarenas 11299. MULTIPOLYGON (((-85.1659 10.01118, -8…
#> 7 San José 4970. POLYGON ((-83.93287 10.18958, -83.934…summarize() permite renombrar las variables, como se muestra seguidamente.
# Ejemplo de renombramiento de variables con summarise()
# Suma total de las áreas de cantones
cantones %>%
summarize(area_km2 = sum(area, na.rm = TRUE),
cantidad_cantones = n())
#> Simple feature collection with 1 feature and 2 fields
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: -87.09455 ymin: 5.498567 xmax: -82.55287 ymax: 11.21964
#> Geodetic CRS: WGS 84
#> area_km2 cantidad_cantones geometry
#> 1 51170.45 82 MULTIPOLYGON (((-84.8775 9....El siguiente ejemplo utiliza otras funciones del paquete dplyr para encontrar las tres provincias más grandes y sus respectivas áreas, con base en los datos disponibles en la capa de cantones.
# Área y cantidad de cantones de las tres provincias más grandes
cantones %>%
st_drop_geometry() %>%
dplyr::select(area, provincia) %>%
group_by(provincia) %>%
summarise(area = sum(area, na.rm = TRUE),
cantidad_cantones = n()) %>%
arrange(desc(area)) %>%
top_n(n = 3, wt = area)
#> # A tibble: 3 × 3
#> provincia area cantidad_cantones
#> <chr> <dbl> <int>
#> 1 Puntarenas 11299. 11
#> 2 Guanacaste 10196. 11
#> 3 Alajuela 9772. 16Ejercicio: mediante summarize(), y otras funciones de dplyr, despliegue el área y la cantidad de cantones de las dos provincias más pequeñas.
14.6.4 Unión de datos
La combinación de datos ubicados en diferentes fuentes es una tarea común en análisis de información. Este tipo de operaciones se realizan con base en atributos que son comunes en los conjuntos de datos que se desea “unir” (join). El paquete dplyr proporciona varios métodos para realizar uniones de datos, entre los que se encuentran:
-
left_join(): mantiene todas las filas del conjunto de datos del lado izquierdo y les agrega las columnas del conjunto de datos del lado derecho, en las filas en las que hay coincidencia. -
inner_join(): incluye las filas que coinciden en ambos conjuntos de datos. -
right_join(): mantiene todas las filas del conjunto de datos del lado derecho y agrega las columnas del conjunto de datos del lado izquierdo, en las filas en las que hay coincidencia. -
full_join(): incluye todas las filas de ambos conjuntos de datos.
Todos los tipos de joins requieren de una o varias columnas que sean comunes a ambos conjuntos de datos, llamadas join keys, en inglés. Esas columnas se especifican con el argumento by. Por ejemplo, by = codigo, si la columna común se llama codigo en ambos conjuntos de datos. Si tienen diferentes nombres, se utiliza un vector (ej. by = c("codigo_1" = "codigo_2"), en donde codigo_1 es el nombre de la columna en el conjunto de datos de la izquierda y codigo_2 en el de la derecha. Si hay columnas con nombres iguales en ambos conjuntos de datos, by utiliza esos nombres por defecto.
14.6.4.1 Ejemplos
14.6.4.1.1 Casos positivos acumulados de covid en cantones
En este caso, se unen los datos geoespaciales de cantones con los datos de casos positivos acumulados de covid-19 en los cantones de Costa Rica. La columna común (join key) se llama cod_canton en ambos conjuntos de datos y contiene el código de cantón asignado por el IGN.
# Unión de los datos geoespaciales de cantones con los de casos positivos de covid.
# Ambas tablas comparten la columna "cod_canton".
cantones_covid_positivos <-
cantones %>%
left_join(
dplyr::select(covid_positivos, cod_canton, positivos), # el select() es para no llevar columnas innecesarias a la unión
by = "cod_canton", # campo común para realizar la unión
copy = FALSE, # para no copiar todos los campos del data frame derecho en el data frame izquierdo
keep = FALSE # # para no copiar el campo de unión
)Con el data frame resultante del join, se generan mapas de coropletas que muestran la cantidad de casos positivos de covid en los cantones. Para estos mapas, se crea un paleta de colores.
# Paleta de colores para los mapas
colores_cantones_covid_positivos <-
colorNumeric(palette = "Reds",
domain = cantones_covid_positivos$positivos,
na.color = "transparent")El resultado se muestra en un mapa generado con plot().
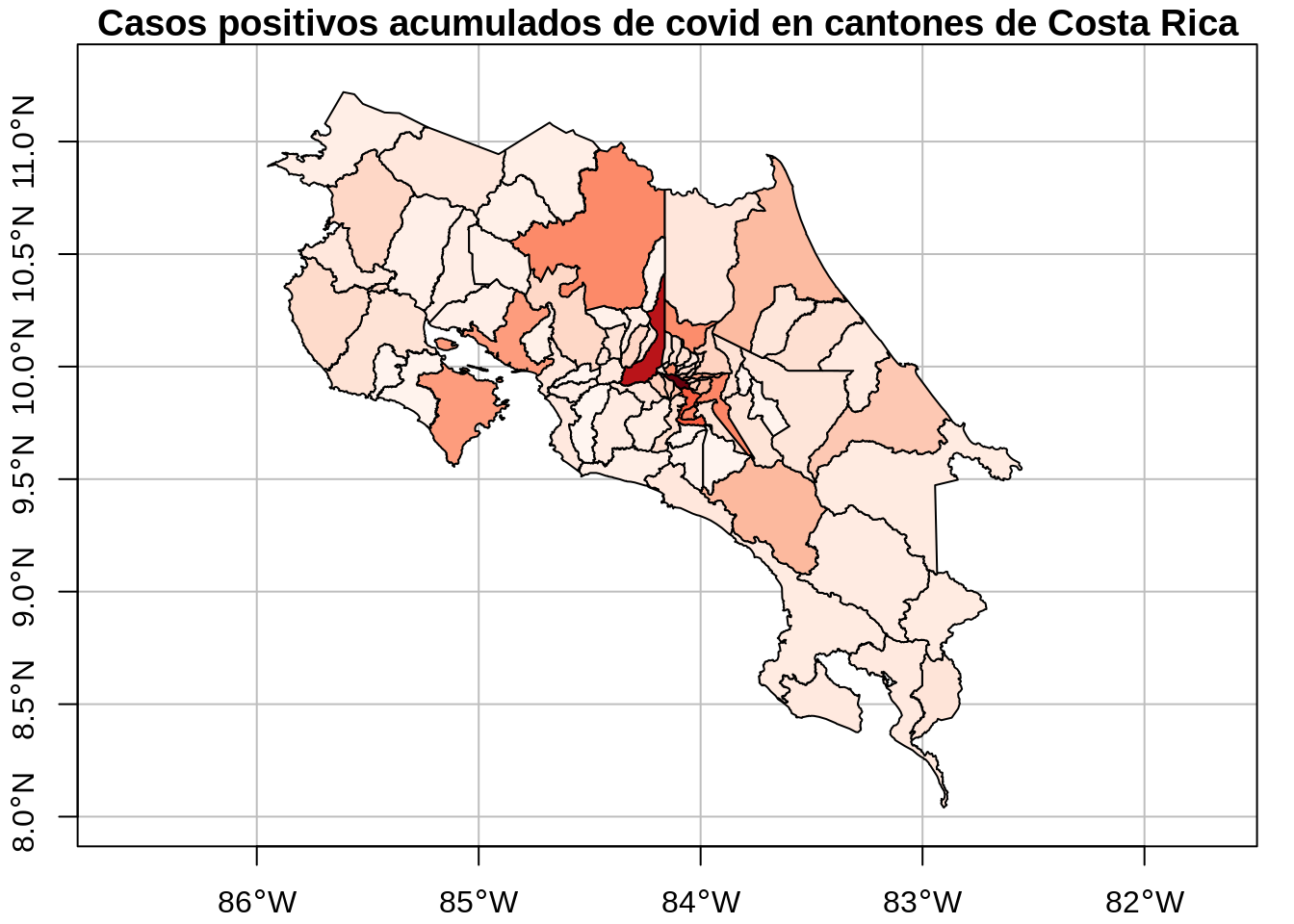
# Visualización en un mapa generado con plot()
plot(
cantones_covid_positivos["positivos"],
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
col = colores_cantones_covid_positivos(cantones_covid_positivos$positivos),
main = "Casos positivos acumulados de covid en cantones de Costa Rica",
axes = TRUE,
graticule = TRUE
)
Y en un mapa generado con leaflet().
# Visualización en un mapa generado con leaflet()
leaflet() %>%
setView(# centro y nivel inicial de acercamiento
lng = -84.19452,
lat = 9.572735,
zoom = 7) %>%
addTiles(group = "OpenStreetMap") %>% # capa base
addPolygons(
# capa de polígonos
data = cantones_covid_positivos,
fillColor = ~ colores_cantones_covid_positivos(cantones_covid_positivos$positivos),
fillOpacity = 0.8,
color = "black",
stroke = TRUE,
weight = 1.0,
popup = paste(
# ventana emergente
paste(
"<strong>Cantón:</strong>",
cantones_covid_positivos$canton
),
paste(
"<strong>Casos:</strong>",
cantones_covid_positivos$positivos
),
sep = '<br/>'
),
group = "Casos positivos acumulados de covid en cantones"
) %>%
addLayersControl(
# control de capas
baseGroups = c("OpenStreetMap"),
overlayGroups = c("Casos positivos acumulados de covid en cantones")
) %>%
addLegend(
# leyenda
position = "bottomleft",
pal = colores_cantones_covid_positivos,
values = cantones_covid_positivos$positivos,
group = "Casos positivos acumulados de covid en cantones",
title = "Cantidad de casos"
)14.6.4.1.2 Delitos
En este ejemplo, se unen los datos geoespaciales de provincias, cantones y distritos con los datos de delitos ocurridos en Costa Rica en el año 2021. El data frame de delitos tiene columnas correspondientes al nombre de la provincia, cantón y distrito en donde ocurrió cada uno. Sin embargo, por exactitud y eficiencia, se prefieren los códigos del IGN a los nombres, por lo que se incluyen a través de uniones con los conjuntos de datos de provincias, cantones y distritos.
14.6.4.1.2.1 En provincias
Se crea el campo provincia_normalizado, en provincias y en delitos, correspondiente al nombre de la provincia, pero en minúsculas, sin acentos, ni eñes ni otros caracteres especiales o propios del idioma español (ej. “san jose”, en lugar de “San José”). Este campo será más fácil de usar para unir las tablas, ya que evitará dificultades por diferencias en mayúsculas, minúsculas, tildes y otras.
# Normalización de los nombres de provincias
# En el data frame de provincias
provincias <-
provincias %>%
mutate(provincia_normalizado = tolower(stri_trans_general(provincia, id = "Latin-ASCII")))
# En el data frame de delitos
delitos <-
delitos %>%
mutate(provincia_normalizado = tolower(stri_trans_general(Provincia, id = "Latin-ASCII")))Mediante un join de los nombres normalizados, se agrega el código de la provincia a delitos.
# Unión del código de provincia a delitos
delitos <-
delitos %>%
left_join(
dplyr::select(
st_drop_geometry(provincias),
cod_provin,
provincia_normalizado
),
by = "provincia_normalizado",
copy = FALSE,
keep = FALSE
)Se cuenta la cantidad de registros por provincia y se une al data frame provincias.
# Conteo de registros por código de provincia
delitos_x_provincia <-
delitos %>%
count(cod_provin, name = "delitos")
# Unión de cantidad de delitos por provincia a provincias
provincias_delitos <-
provincias %>%
left_join(
delitos_x_provincia,
by = "cod_provin",
copy = FALSE,
keep = FALSE
)
# Visualización en formato de tabla
provincias_delitos %>%
st_drop_geometry() %>%
select(provincia, delitos) %>%
arrange(desc(delitos)) %>%
datatable(options = list(
pageLength = 10,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))Paleta de colores para los mapas de coropletas.
# Paleta de colores para los mapas
colores_provincias_delitos <-
colorNumeric(palette = "Reds",
domain = provincias_delitos$delitos,
na.color = "transparent")Mapa de coropletas generado con plot().
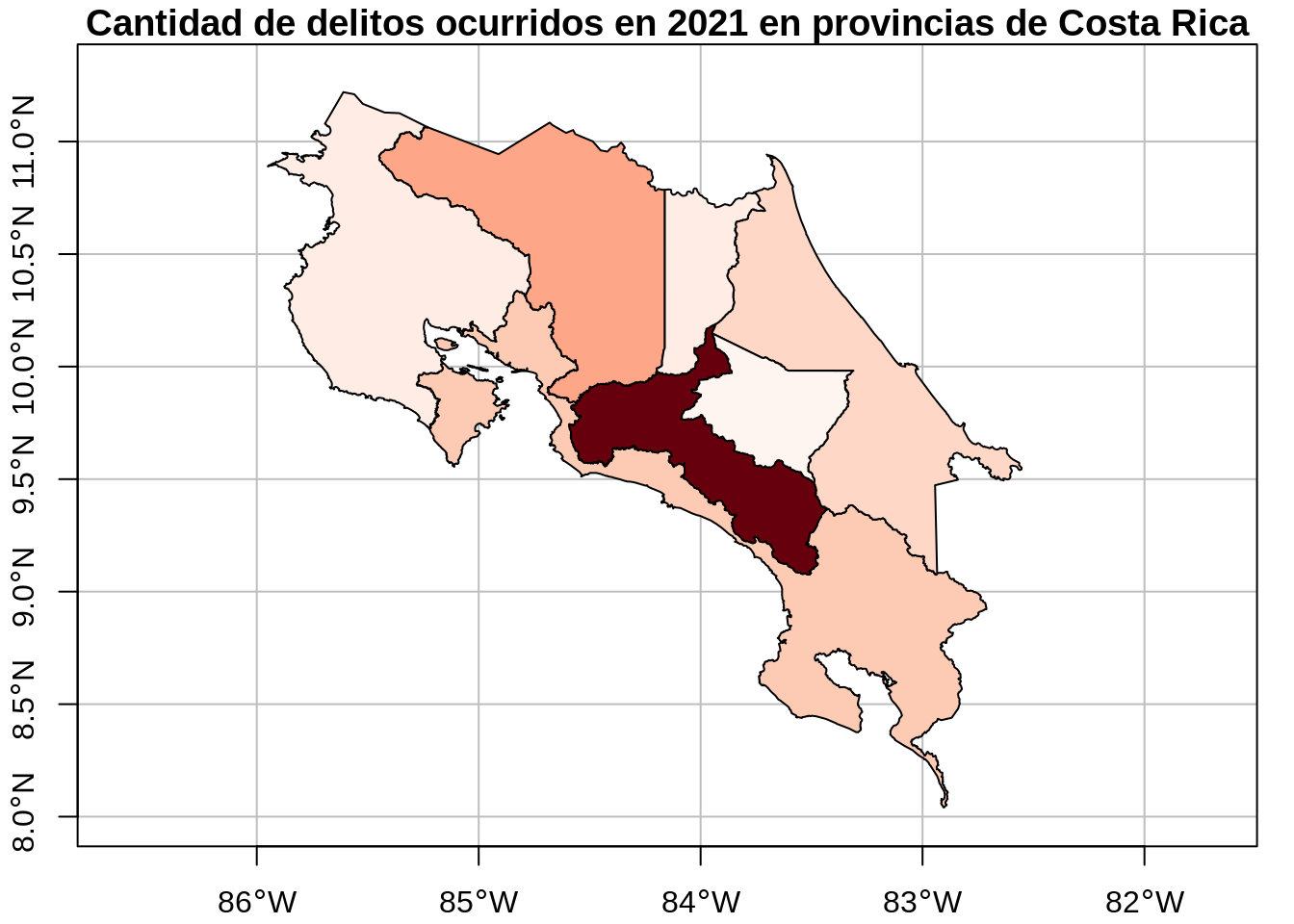
# Visualización en un mapa generado con plot()
plot(
provincias_delitos["delitos"],
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
col = colores_provincias_delitos(provincias_delitos$delitos),
main = "Cantidad de delitos ocurridos en 2021 en provincias de Costa Rica",
axes = TRUE,
graticule = TRUE
)
Mapa de coropletas generado con leaflet().
# Mapa leaflet de delitos en provincias
leaflet() %>%
setView(# centro y nivel inicial de acercamiento
lng = -84.19452,
lat = 9.572735,
zoom = 7) %>%
addTiles(group = "OpenStreetMap") %>% # capa base
addPolygons(
# capa de polígonos
data = provincias_delitos,
fillColor = ~ colores_provincias_delitos(provincias_delitos$delitos),
fillOpacity = 0.8,
color = "black",
stroke = TRUE,
weight = 1.0,
popup = paste(
# ventana emergente
paste(
"<strong>Provincia:</strong>",
provincias_delitos$provincia
),
paste(
"<strong>Delitos:</strong>",
provincias_delitos$delitos
),
sep = '<br/>'
),
group = "Delitos en provincias"
) %>%
addLayersControl(
# control de capas
baseGroups = c("OpenStreetMap"),
overlayGroups = c("Delitos en provincias")
) %>%
addLegend(
# leyenda
position = "bottomleft",
pal = colores_provincias_delitos,
values = provincias_delitos$delitos,
group = "Delitos",
title = "Cantidad de delitos"
)14.6.4.1.2.2 En cantones
Primero, se corrigen algunos nombres de cantones en delitos, con el fin de que sean iguales a los de cantones, el conjunto de datos oficial del IGN.
Se crea el campo canton_normalizado, en cantones y en delitos, correspondiente al nombre del cantón, en minúscula y sin acentos ni caracteres especiales.
# Normalización de los nombres de cantones
# En el data frame de cantones
cantones <-
cantones %>%
mutate(canton_normalizado = tolower(stri_trans_general(canton, id = "Latin-ASCII")))
# En el data frame de delitos
delitos <-
delitos %>%
mutate(canton_normalizado = tolower(stri_trans_general(Canton, id = "Latin-ASCII")))Luego, mediante un join, se obtienen los nombres de cantones en delitos que no están en cantones.
delitos %>%
left_join(
dplyr::select(st_drop_geometry(cantones),
canton_normalizado, cod_canton),
by = "canton_normalizado",
copy = FALSE,
keep = FALSE
) %>%
filter(is.na(cod_canton) & canton_normalizado != "desconocido") %>% # los cod_canton = NA son los que no están en el data frame de cantones
distinct(canton_normalizado) # se despliegan solo los nombres de cantones diferentes
#> # A tibble: 2 × 1
#> canton_normalizado
#> <chr>
#> 1 leon cortes
#> 2 vasquez de coronadoLos anteriores, son los nombres de cantones en delitos sin coincidencia en cantones. En el siguiente bloque de código, se corrigen esos nombres de acuerdo con los de cantones.
# Corrección de nombres de cantones en delitos
delitos <-
delitos %>%
mutate(Canton = if_else(Canton == "LEON CORTES", "LEON CORTES CASTRO", Canton)) %>%
mutate(Canton = if_else(Canton == "VASQUEZ DE CORONADO", "VAZQUEZ DE CORONADO", Canton))
# Se realiza nuevamente esta operación para reflejar los cambios en los nombres de cantones
delitos <-
delitos %>%
mutate(canton_normalizado = tolower(stri_trans_general(Canton, id = "Latin-ASCII")))
# Revisión
delitos %>%
left_join(
dplyr::select(st_drop_geometry(cantones),
canton_normalizado, cod_canton),
by = "canton_normalizado",
copy = FALSE,
keep = FALSE
) %>%
filter(is.na(cod_canton) & canton_normalizado != "desconocido") %>% # los cod_canton = NA son los que no están en el data frame de cantones
distinct(canton_normalizado) # se despliegan solo los nombres de cantones diferentes
#> # A tibble: 0 × 1
#> # … with 1 variable: canton_normalizado <chr>Mediante un join de los nombres normalizados, se agrega el código del cantón a delitos.
# Unión del código de cantón a delitos
delitos <-
delitos %>%
left_join(
dplyr::select(
st_drop_geometry(cantones),
cod_canton,
canton_normalizado
),
by = "canton_normalizado",
copy = FALSE,
keep = FALSE
)Se cuenta la cantidad de registros por cantón y se une al data frame cantones.
# Conteo de registros por código de cantón
delitos_x_canton <-
delitos %>%
count(cod_canton, name = "delitos")
# Unión de cantidad de delitos por cantón a cantones
cantones_delitos <-
cantones %>%
left_join(
delitos_x_canton,
by = "cod_canton",
copy = FALSE,
keep = FALSE
)
# Visualización en formato de tabla
cantones_delitos %>%
st_drop_geometry() %>%
select(canton, delitos) %>%
arrange(desc(delitos)) %>%
datatable(options = list(
pageLength = 10,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))Paleta de colores para los mapas de coropletas.
# Paleta de colores para los mapas
colores_cantones_delitos <-
colorNumeric(palette = "Reds",
domain = cantones_delitos$delitos,
na.color = "transparent")Mapa de coropletas generado con plot().
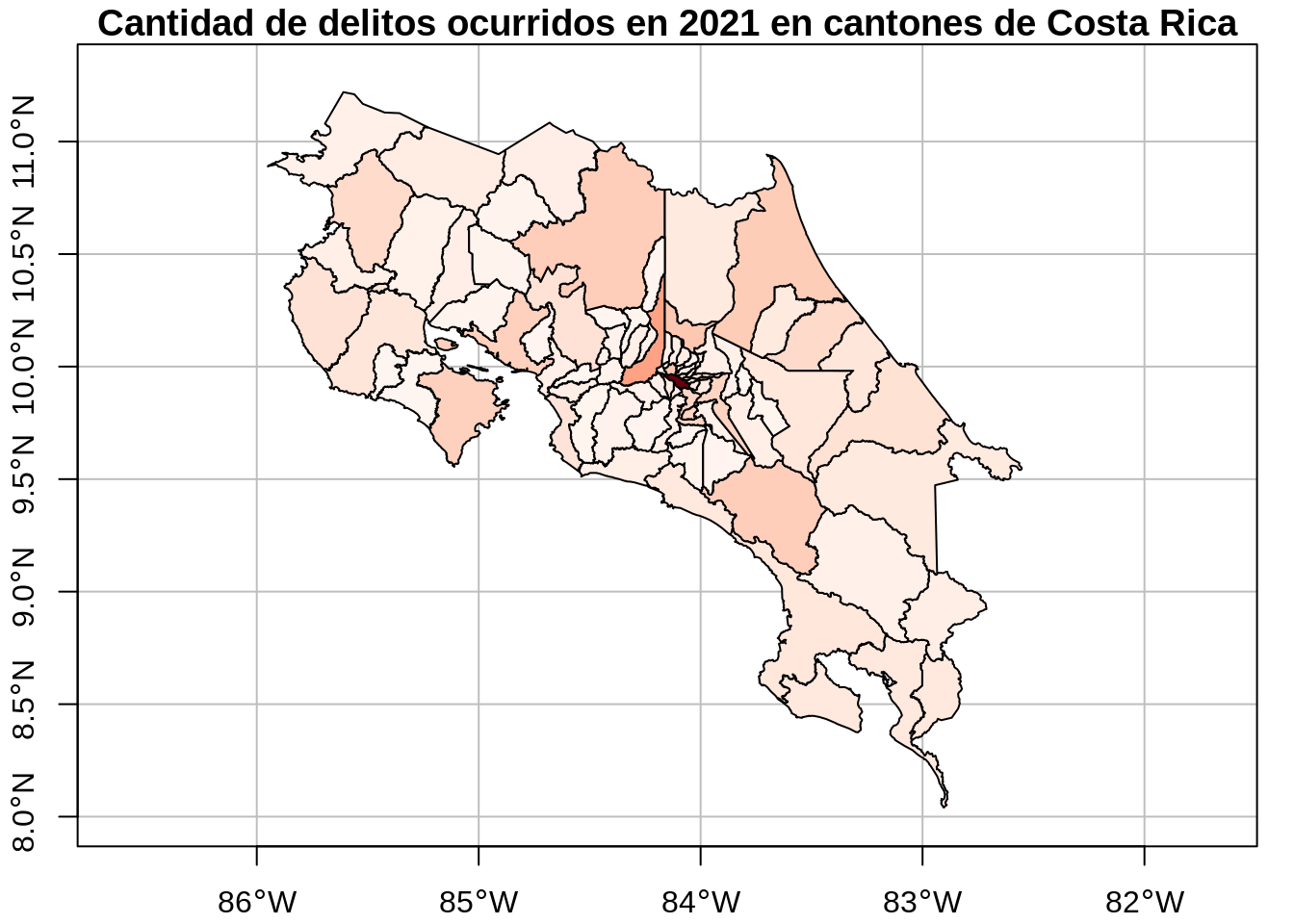
# Visualización en un mapa generado con plot()
plot(
cantones_delitos["delitos"],
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
col = colores_cantones_delitos(cantones_delitos$delitos),
main = "Cantidad de delitos ocurridos en 2021 en cantones de Costa Rica",
axes = TRUE,
graticule = TRUE
)
Mapa de coropletas generado con leaflet().
# Mapa leaflet de delitos en cantones
leaflet() %>%
setView(# centro y nivel inicial de acercamiento
lng = -84.19452,
lat = 9.572735,
zoom = 7) %>%
addTiles(group = "OpenStreetMap") %>% # capa base
addPolygons(
# capa de polígonos
data = cantones_delitos,
fillColor = ~ colores_cantones_delitos(cantones_delitos$delitos),
fillOpacity = 0.8,
color = "black",
stroke = TRUE,
weight = 1.0,
popup = paste(
# ventana emergente
paste(
"<strong>Cantón:</strong>",
cantones_delitos$canton
),
paste(
"<strong>Delitos:</strong>",
cantones_delitos$delitos
),
sep = '<br/>'
),
group = "Delitos en cantones"
) %>%
addLayersControl(
# control de capas
baseGroups = c("OpenStreetMap"),
overlayGroups = c("Delitos en cantones")
) %>%
addLegend(
# leyenda
position = "bottomleft",
pal = colores_cantones_delitos,
values = cantones_delitos$delitos,
group = "Delitos",
title = "Cantidad de delitos"
)14.6.4.1.2.3 En distritos
Primero, se corrigen algunos nombres de distritos en delitos, con el fin de que sean iguales a los de distritos, el conjunto de datos oficial del IGN.
Se crea el campo distrito_normalizado, en distritos y en delitos, el cual corresponde al nombre del distrito, en minúscula y sin acentos ni caracteres especiales. El nombre de un distrito debe consultarse conjuntamente con el código del cantón (cod_canton), debido a que el nombre del distrito solamente es único si se asocia con su cantón. Por ejemplo, existen varios distritos llamados “Concepción”, pero pertenecientes a diferentes cantones.
# Normalización de los nombres de distritos
# En el data frame de distritos
distritos <-
distritos %>%
mutate(distrito_normalizado = tolower(stri_trans_general(distrito, id = "Latin-ASCII")))
# En el data frame de delitos
delitos <-
delitos %>%
mutate(distrito_normalizado = tolower(stri_trans_general(Distrito, id = "Latin-ASCII")))Luego, mediante un join, se obtienen los nombres de cantones en delitos que no están en distritos.
delitos %>%
left_join(
dplyr::select(st_drop_geometry(distritos),
codigo_dta,
cod_canton,
distrito_normalizado
),
by = c("cod_canton" = "cod_canton", "distrito_normalizado" = "distrito_normalizado"),
copy = FALSE,
keep = FALSE
) %>%
filter(is.na(codigo_dta) & distrito_normalizado != "desconocido") %>% # los cod_dta = NA son los que no están en el data frame de distritos
distinct(cod_canton, Canton, distrito_normalizado) %>% # se despliegan solo los nombres diferentes de distritos (tomando en cuenta el cantón)
print(n = Inf)
#> # A tibble: 31 × 3
#> Canton cod_canton distrito_normalizado
#> <chr> <int> <chr>
#> 1 SIQUIRRES 703 cairo
#> 2 SAN CARLOS 210 fortuna
#> 3 SARAPIQUI 410 horquetas
#> 4 PEREZ ZELEDON 119 general
#> 5 BARVA 402 san jose de la monta?a
#> 6 ESPARZA 602 macacoma
#> 7 CARTAGO 301 san francisco
#> 8 OROTINA 209 ceiba
#> 9 OSA 605 cortes
#> 10 ALAJUELA 201 la garita
#> 11 PEREZ ZELEDON 119 la amistad
#> 12 UPALA 213 san jose (pizote)
#> 13 GOLFITO 607 jimenez
#> 14 SAN RAFAEL 405 los angeles
#> 15 CARTAGO 301 guadalupe
#> 16 BELEN 407 asuncion
#> 17 OROTINA 209 mastate
#> 18 MONTES DE ORO 604 union
#> 19 GOICOECHEA 108 mata platano
#> 20 COTO BRUS 608 agua buena
#> 21 NARANJO 206 rosario
#> 22 SAN CARLOS 210 palmera
#> 23 SAN CARLOS 210 tigra
#> 24 GUACIMO 706 merecedes
#> 25 BAGACES 504 fortuna
#> 26 OSA 605 drake
#> 27 PALMARES 207 granja
#> 28 SARAPIQUI 410 cure?a
#> 29 TURRIALBA 305 el chirripo
#> 30 ASERRI 106 la legua
#> 31 ZARCERO 211 tapezcoLos anteriores, son los nombres de cantones en delitos sin coincidencia en distritos. En el siguiente bloque de código, se corrigen esos nombres de acuerdo con los de distritos.
# Corrección de nombres de distritos en el data frame de delitos
delitos <-
delitos %>%
mutate(Distrito = if_else(cod_canton == 703 & Distrito == "CAIRO", "EL CAIRO", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 210 & Distrito == "FORTUNA", "LA FORTUNA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 410 & Distrito == "HORQUETAS", "LAS HORQUETAS", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 119 & Distrito == "GENERAL", "EL GENERAL", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 402 & Distrito == "SAN JOSE DE LA MONTA?A", "SAN JOSE DE LA MONTANA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 602 & Distrito == "MACACOMA", "MACACONA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 301 & Distrito == "SAN FRANCISCO", "AGUACALIENTE O SAN FRANCISCO", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 209 & Distrito == "CEIBA", "LA CEIBA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 605 & Distrito == "CORTES", "PUERTO CORTES", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 201 & Distrito == "LA GARITA", "GARITA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 119 & Distrito == "LA AMISTAD", "LA AMISTAD", Distrito)) %>% # el nombre del IGN tiene un espacio en blanco de más
mutate(Distrito = if_else(cod_canton == 213 & Distrito == "SAN JOSE (PIZOTE)", "SAN JOSE O PIZOTE", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 607 & Distrito == "JIMENEZ", "PUERTO JIMENEZ", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 405 & Distrito == "LOS ANGELES", "ANGELES", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 301 & Distrito == "GUADALUPE", "GUADALUPE O ARENILLA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 407 & Distrito == "ASUNCION", "LA ASUNCION", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 209 & Distrito == "MASTATE", "EL MASTATE", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 604 & Distrito == "UNION", "LA UNION", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 108 & Distrito == "MATA PLATANO", "MATA DE PLATANO", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 608 & Distrito == "AGUA BUENA", "AGUABUENA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 206 & Distrito == "ROSARIO", "EL ROSARIO", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 210 & Distrito == "PALMERA", "LA PALMERA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 210 & Distrito == "TIGRA", "LA TIGRA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 706 & Distrito == "MERECEDES", "MERCEDES", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 504 & Distrito == "FORTUNA", "LA FORTUNA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 605 & Distrito == "DRAKE", "BAHIA DRAKE", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 207 & Distrito == "GRANJA", "LA GRANJA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 410 & Distrito == "CURE?A", "CURENA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 305 & Distrito == "EL CHIRRIPO", "CHIRRIPO", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 106 & Distrito == "LA LEGUA", "LEGUA", Distrito)) %>%
mutate(Distrito = if_else(cod_canton == 211 & Distrito == "TAPEZCO", "TAPESCO", Distrito))
# Se realiza nuevamente esta operación para reflejar los cambios en los nombres de distritos
delitos <-
delitos %>%
mutate(distrito_normalizado = tolower(stri_trans_general(Distrito, id = "Latin-ASCII")))
# Revisión
delitos %>%
left_join(
dplyr::select(st_drop_geometry(distritos),
codigo_dta,
cod_canton,
distrito_normalizado
),
by = c("cod_canton" = "cod_canton", "distrito_normalizado" = "distrito_normalizado"),
copy = FALSE,
keep = FALSE
) %>%
filter(is.na(codigo_dta) & distrito_normalizado != "desconocido") %>% # los cod_dta = NA son los que no están en el data frame de distritos
distinct(cod_canton, Canton, distrito_normalizado) %>% # se despliegan solo los nombres diferentes de distritos (tomando en cuenta el cantón)
print(n = Inf)
#> # A tibble: 0 × 3
#> # … with 3 variables: Canton <chr>, cod_canton <int>,
#> # distrito_normalizado <chr>Mediante un join de los nombres normalizados, se agrega el código del distrito (codigo_dta) a delitos.
# Unión del código de distrito a delitos
delitos <-
delitos %>%
left_join(
dplyr::select(
st_drop_geometry(distritos),
codigo_dta,
cod_canton,
distrito_normalizado
),
by = c("cod_canton" = "cod_canton", "distrito_normalizado" = "distrito_normalizado"),
copy = FALSE,
keep = FALSE
)Se cuenta la cantidad de delitos por distrito y se une al data frame distritos.
# Conteo de delitos por código de distrito
delitos_x_distrito <-
delitos %>%
count(codigo_dta, name = "delitos")
# Unión de cantidad de delitos por distrito a distritos
distritos_delitos <-
distritos %>%
left_join(
delitos_x_distrito,
by = "codigo_dta",
copy = FALSE,
keep = FALSE
) %>%
mutate(delitos = ifelse(is.na(delitos), 0, delitos)) # para sustituir los NA con 0
# Visualización en formato de tabla
distritos_delitos %>%
st_drop_geometry() %>%
select(provincia, canton, codigo_dta, distrito, delitos) %>%
arrange(desc(delitos)) %>%
datatable(options = list(
pageLength = 10,
language = list(url = '//cdn.datatables.net/plug-ins/1.10.11/i18n/Spanish.json')
))Paleta de colores para los mapas de coropletas.
# Paleta de colores para los mapas
colores_distritos_delitos <-
colorNumeric(palette = "Reds",
domain = distritos_delitos$delitos,
na.color = "transparent")Mapa de coropletas generado con plot().
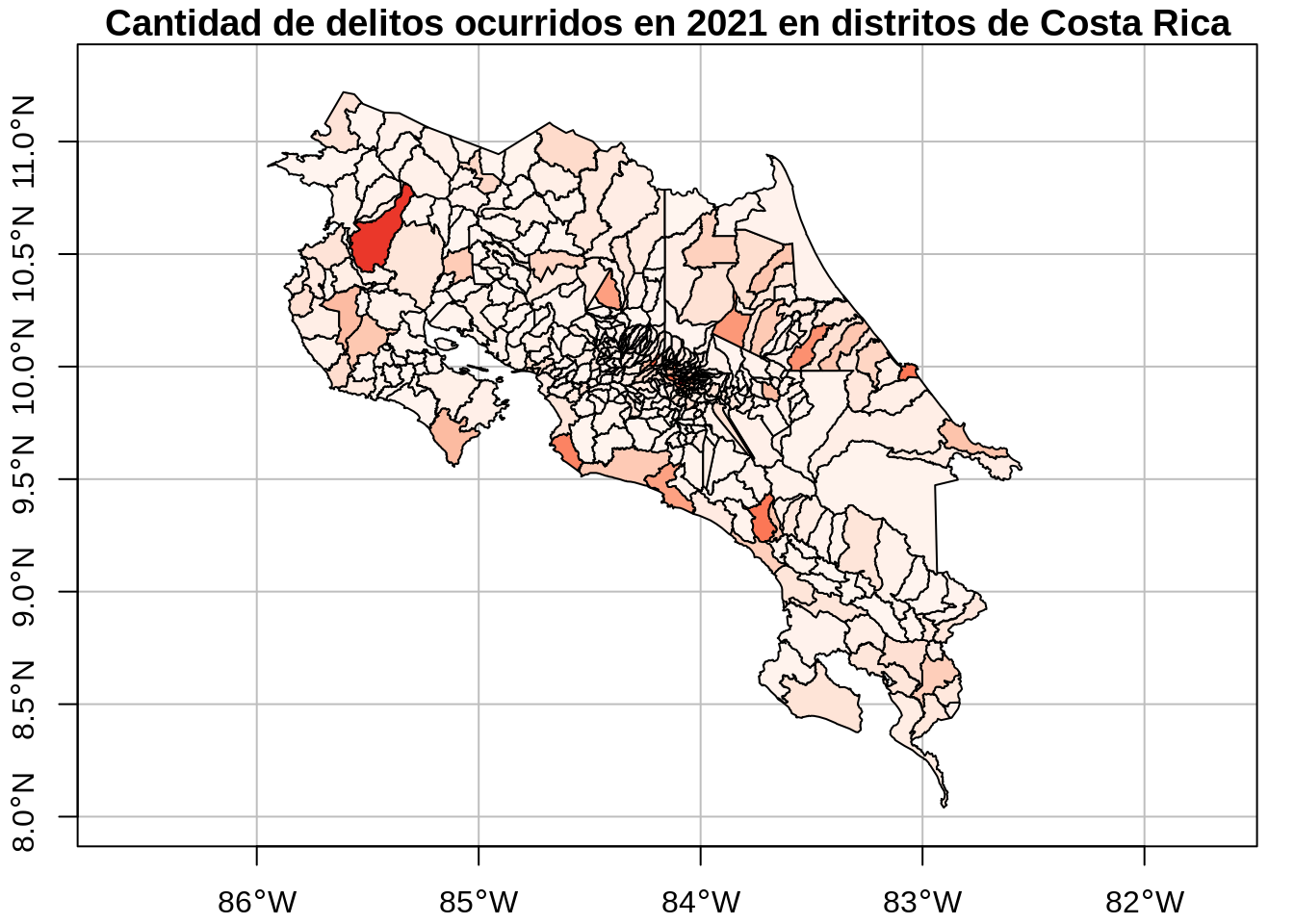
# Visualización en un mapa generado con plot()
plot(
distritos_delitos["delitos"],
extent = st_bbox(c(xmin = -86.0, xmax = -82.3, ymin = 8.0, ymax = 11.3)),
col = colores_distritos_delitos(distritos_delitos$delitos),
main = "Cantidad de delitos ocurridos en 2021 en distritos de Costa Rica",
axes = TRUE,
graticule = TRUE
)
Mapa de coropletas generado con leaflet().
# Mapa leaflet de delitos en distritos
leaflet() %>%
setView(# centro y nivel inicial de acercamiento
lng = -84.19452,
lat = 9.572735,
zoom = 7) %>%
addTiles(group = "OpenStreetMap") %>% # capa base
addPolygons(
# capa de polígonos
data = distritos_delitos,
fillColor = ~ colores_distritos_delitos(distritos_delitos$delitos),
fillOpacity = 0.8,
color = "black",
stroke = TRUE,
weight = 1.0,
popup = paste(
# ventana emergente
paste(
"<strong>Cantón:</strong>",
distritos_delitos$canton
),
paste(
"<strong>Distrito:</strong>",
distritos_delitos$distrito
),
paste(
"<strong>Delitos:</strong>",
distritos_delitos$delitos
),
sep = '<br/>'
),
group = "Delitos en distritos"
) %>%
addLayersControl(
# control de capas
baseGroups = c("OpenStreetMap"),
overlayGroups = c("Delitos en distritos")
) %>%
addLegend(
# leyenda
position = "bottomleft",
pal = colores_distritos_delitos,
values = distritos_delitos$delitos,
group = "Delitos en distritos",
title = "Cantidad de delitos"
)14.7 Datos raster
Las operaciones con atributos en datos raster incluyen:
- Creación de subconjuntos (subsetting).
- Resumen de información (summarizing).
Seguidamente, se explicará como maneja estas operaciones el paquete terra.
14.8 Manejo de datos de atributos con el paquete terra
14.8.1 Funciones básicas para manejo de objetos SpatRaster
El siguiente bloque de código crea y mapea un objeto SpatRaster llamado elevacion.
# Creación de un objeto SpatRaster
elevacion <- rast(
nrows = 6,
ncols = 6,
resolution = 0.5,
xmin = -1.5,
xmax = 1.5,
ymin = -1.5,
ymax = 1.5,
vals = 1:36
)
# Mapeo
plot(elevacion)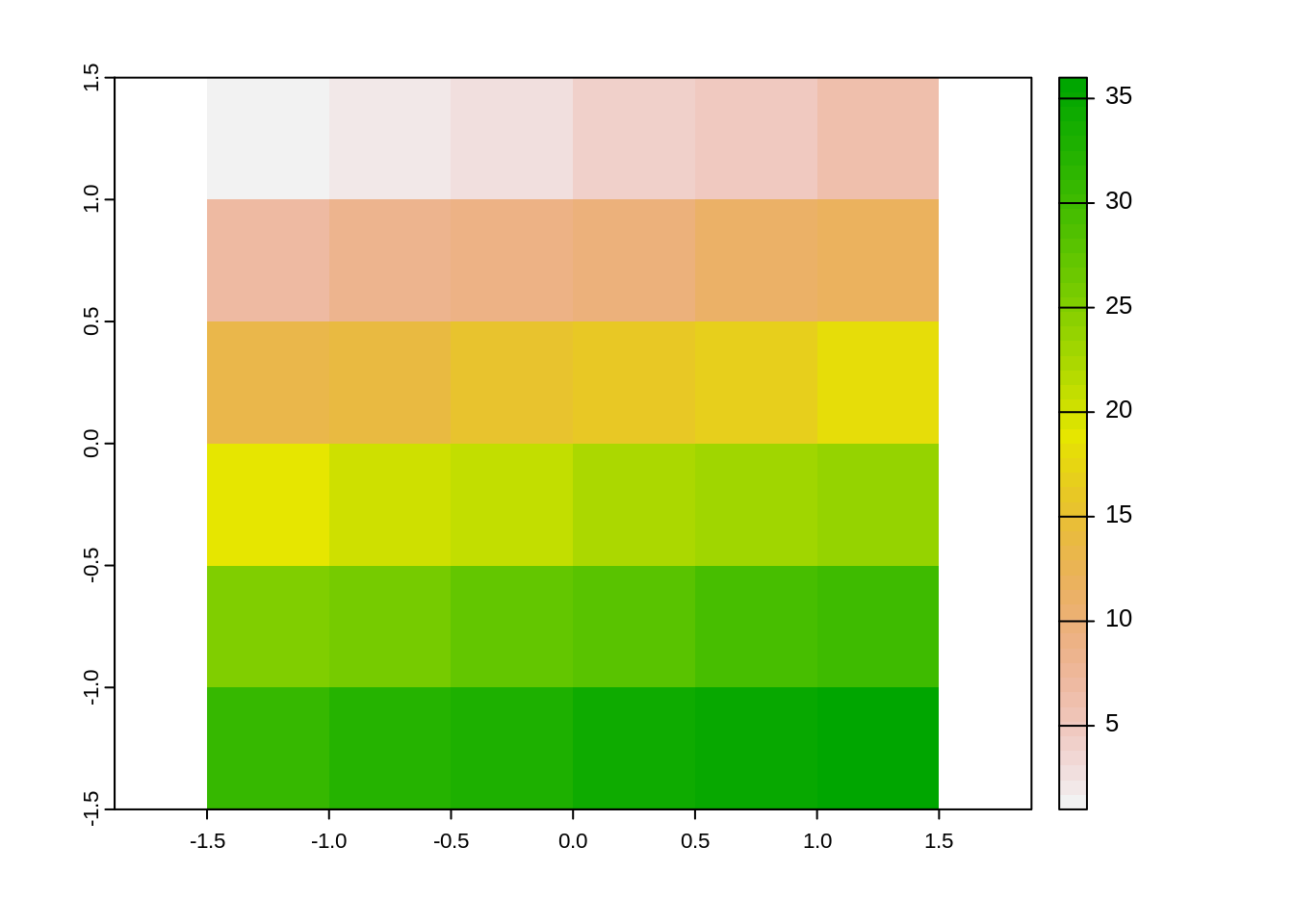
Los objetos SpatRaster también pueden contener valores categóricos de tipo logical o factor. El siguiente bloque de código crea y mapea un objeto SpatRaster con información sobre tipos de granos (i.e. partículas) de una porción de suelo.
# Tipos de granos
grano_tipo <- c("arcilla", "limo", "arena")
# Lista de granos generada aleatoriamente
lista_granos <- sample(grano_tipo, 36, replace = TRUE)
lista_granos
#> [1] "limo" "limo" "limo" "arena" "arena"
#> [6] "arena" "arena" "limo" "limo" "arena"
#> [11] "arcilla" "limo" "limo" "arcilla" "arcilla"
#> [16] "arena" "arena" "limo" "limo" "arcilla"
#> [21] "limo" "arcilla" "arena" "arcilla" "arcilla"
#> [26] "limo" "limo" "arcilla" "arcilla" "limo"
#> [31] "arena" "arena" "arena" "limo" "arcilla"
#> [36] "arena"
# Factor de tipos de granos
grano_factor <- factor(lista_granos, levels = grano_tipo)
# Objeto SpatRaster de tipos de granos
grano <- rast(
nrows = 6,
ncols = 6,
resolution = 0.5,
xmin = -1.5,
xmax = 1.5,
ymin = -1.5,
ymax = 1.5,
vals = grano_factor
)
# Mapeo
plot(grano)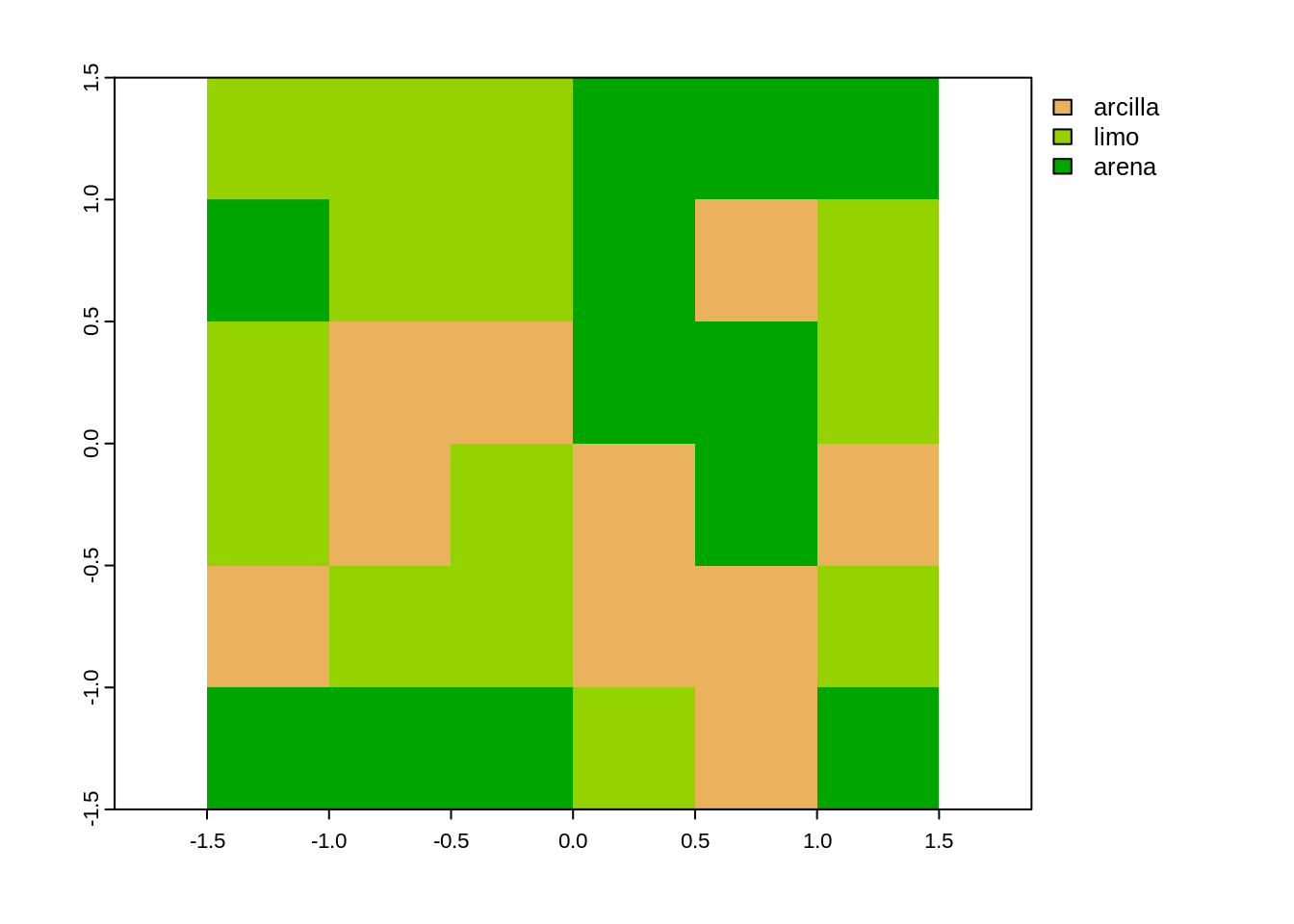
Ambos objetos pueden guardados en el disco con la función writeRaster().
# Especificación del directorio de trabajo (debe ser una ruta existente)
setwd("/home/mfvargas")
# Escritura de los objetos raster
writeRaster(elevacion, "elevacion.asc")
writeRaster(grano, "grano.asc")La función levels() puede utilizarse para consultar la Raster Attribute Table (RAT) de un objeto SpatRaster, la cual contiene información sobre sus factores y niveles. También puede emplearse para asignar nuevos factores a un objeto.
# Consulta de la RAT
levels(grano)
#> [[1]]
#> [1] "arcilla" "limo" "arena"
# Nuevo factor
levels(grano) = data.frame(value = c(0, 1, 2), wetness = c("mojado", "húmedo", "seco"))
# Consulta de la RAT
levels(grano)
#> [[1]]
#> [1] "mojado" "húmedo" "seco"Los raster categóricos también pueden almacenar información relacionada con los colores de cada valor, mediante una tabla. La tabla de colores es un data frame con tres (red, green, blue) o cuatro (alpha) columnas, en la que cada fila corresponde a un valor. Las tablas de colores en terra pueden consultarse o modificarse con la función coltab().
14.8.2 Creación de subconjuntos
Los subconjuntos se crean en objetos SpatRaster con el operador [, el cual acepta varios tipos de entradas.
- Índices de filas y columnas.
- ID de celdas.
- Coordenadas.
- Otros objetos espaciales.
En este capítulo, solo se tratarán las dos primeras opciones. Las restantes se cubrirán en las secciones sobre operaciones espaciales.
Las dos primeras opciones se ilustran en el siguiente bloque de código, en el que se consulta la celda (también llamada pixel) ubicada en la esquina superior izquierda del objeto de elevación.
# Celda en la fila 1, columna 1
elevacion[1, 1]
#> lyr.1
#> 1 1
elevacion[]
#> lyr.1
#> [1,] 1
#> [2,] 2
#> [3,] 3
#> [4,] 4
#> [5,] 5
#> [6,] 6
#> [7,] 7
#> [8,] 8
#> [9,] 9
#> [10,] 10
#> [11,] 11
#> [12,] 12
#> [13,] 13
#> [14,] 14
#> [15,] 15
#> [16,] 16
#> [17,] 17
#> [18,] 18
#> [19,] 19
#> [20,] 20
#> [21,] 21
#> [22,] 22
#> [23,] 23
#> [24,] 24
#> [25,] 25
#> [26,] 26
#> [27,] 27
#> [28,] 28
#> [29,] 29
#> [30,] 30
#> [31,] 31
#> [32,] 32
#> [33,] 33
#> [34,] 34
#> [35,] 35
#> [36,] 36
# Celda con ID = 1
elevacion[1]
#> lyr.1
#> 1 1La totalidad de los valores de un objeto SpatRaster puede consultarse con las función values().
# Valores de un objeto raster
values(elevacion)
#> lyr.1
#> [1,] 1
#> [2,] 2
#> [3,] 3
#> [4,] 4
#> [5,] 5
#> [6,] 6
#> [7,] 7
#> [8,] 8
#> [9,] 9
#> [10,] 10
#> [11,] 11
#> [12,] 12
#> [13,] 13
#> [14,] 14
#> [15,] 15
#> [16,] 16
#> [17,] 17
#> [18,] 18
#> [19,] 19
#> [20,] 20
#> [21,] 21
#> [22,] 22
#> [23,] 23
#> [24,] 24
#> [25,] 25
#> [26,] 26
#> [27,] 27
#> [28,] 28
#> [29,] 29
#> [30,] 30
#> [31,] 31
#> [32,] 32
#> [33,] 33
#> [34,] 34
#> [35,] 35
#> [36,] 36El operador [ también puede utilizarse para modificar los valores de las celdas un objeto SpatRaster.
# Modificación de una celda
elevacion[1, 1] = 0
# Consulta de todos los valores del raster (equivalente a values())
elevacion[]
#> lyr.1
#> [1,] 0
#> [2,] 2
#> [3,] 3
#> [4,] 4
#> [5,] 5
#> [6,] 6
#> [7,] 7
#> [8,] 8
#> [9,] 9
#> [10,] 10
#> [11,] 11
#> [12,] 12
#> [13,] 13
#> [14,] 14
#> [15,] 15
#> [16,] 16
#> [17,] 17
#> [18,] 18
#> [19,] 19
#> [20,] 20
#> [21,] 21
#> [22,] 22
#> [23,] 23
#> [24,] 24
#> [25,] 25
#> [26,] 26
#> [27,] 27
#> [28,] 28
#> [29,] 29
#> [30,] 30
#> [31,] 31
#> [32,] 32
#> [33,] 33
#> [34,] 34
#> [35,] 35
#> [36,] 36
# Modificación de rangos de celdas
elevacion[1, c(1, 2)] = 0
elevacion[1, 1:6] = 0
elevacion[2, 1:6] = 10
elevacion[3, 1:6] = 15
elevacion[4, 1:6] = 15
elevacion[5, 1:6] = 20
elevacion[6, 1:6] = 35
# Consulta de los valores
elevacion[]
#> lyr.1
#> [1,] 0
#> [2,] 0
#> [3,] 0
#> [4,] 0
#> [5,] 0
#> [6,] 0
#> [7,] 10
#> [8,] 10
#> [9,] 10
#> [10,] 10
#> [11,] 10
#> [12,] 10
#> [13,] 15
#> [14,] 15
#> [15,] 15
#> [16,] 15
#> [17,] 15
#> [18,] 15
#> [19,] 15
#> [20,] 15
#> [21,] 15
#> [22,] 15
#> [23,] 15
#> [24,] 15
#> [25,] 20
#> [26,] 20
#> [27,] 20
#> [28,] 20
#> [29,] 20
#> [30,] 20
#> [31,] 35
#> [32,] 35
#> [33,] 35
#> [34,] 35
#> [35,] 35
#> [36,] 3514.8.3 Resumen y sumarización de información
La escritura del nombre de un objeto SpatRaster en la consola imprime información general sobre ese objeto. La función summary() proporciona algunas estadísticas descriptivas (mínimo, máximo, cuartiles, etc.). Otras estadísticas pueden ser calculadas con la función global().
# Información general
elevacion
#> class : SpatRaster
#> dimensions : 6, 6, 1 (nrow, ncol, nlyr)
#> resolution : 0.5, 0.5 (x, y)
#> extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
#> coord. ref. : lon/lat WGS 84
#> source : memory
#> name : lyr.1
#> min value : 0
#> max value : 35
# Resumen de un raster de una capa
summary(elevacion)
#> lyr.1
#> Min. : 0.00
#> 1st Qu.:10.00
#> Median :15.00
#> Mean :15.83
#> 3rd Qu.:20.00
#> Max. :35.00
# Desviación estándar
global(elevacion, sd)
#> sd
#> lyr.1 10.72381Adicionalmente, la función freq() retorna la tabla de frecuencias de valores categóricos.
# Tabla de frecuencias
freq(grano)
#> layer value count
#> 1 1 mojado 10
#> 2 1 húmedo 14
#> 3 1 seco 12Las estadísticas pueden ser visualizadas con funciones como hist() y density().
# Histograma
hist(elevacion)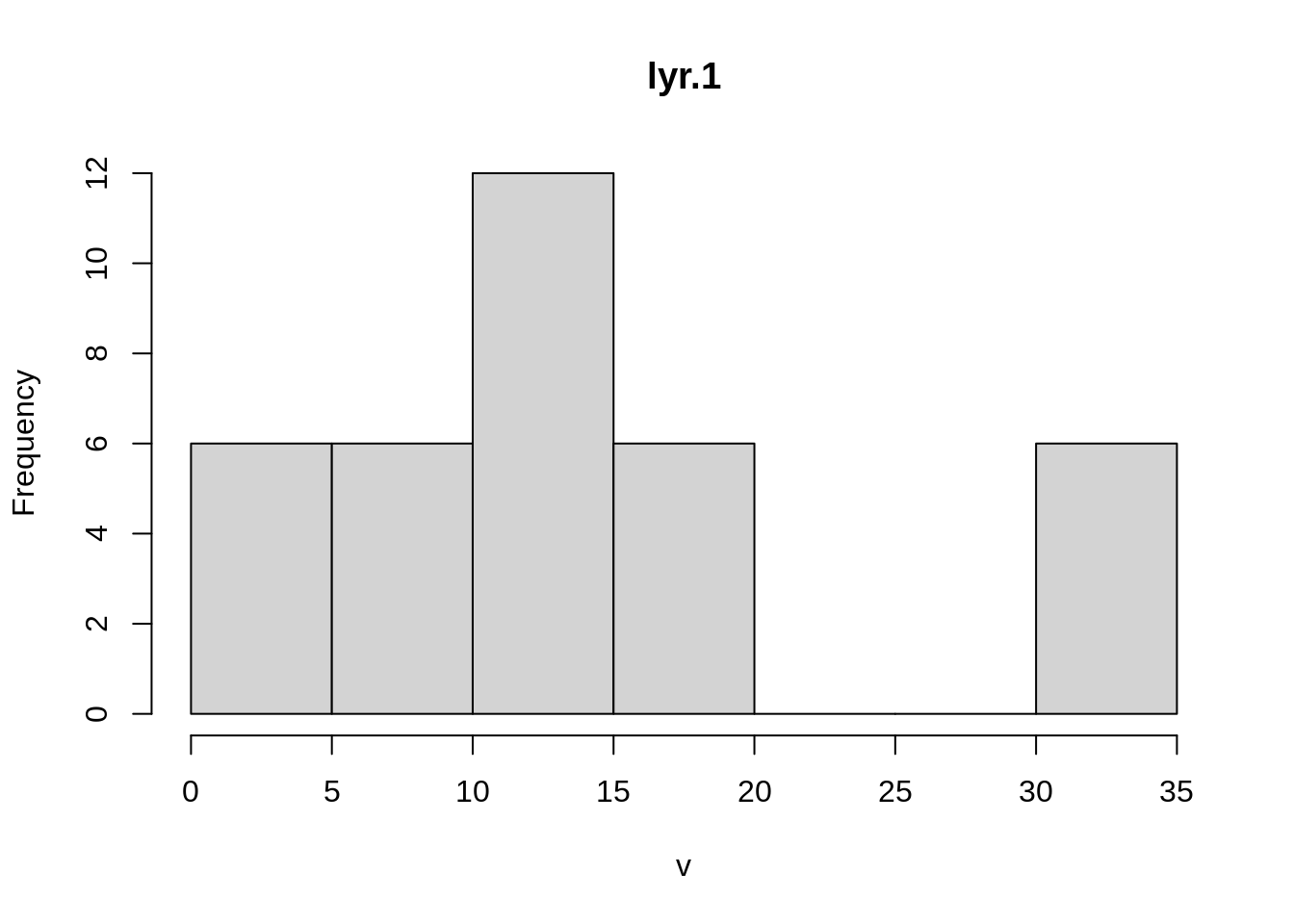
# Densidad
density(elevacion)