12 Paquetes de R para graficación estadística
12.1 Opciones generales
Se configuran opciones generales de la sesión R.
# Configuración de la notación científica
options(scipen = 7)12.2 Trabajo previo
12.2.1 Lecturas
Chang, W. (2018). R graphics cookbook: Practical recipes for visualizing data. O’Reilly. https://r-graphics.org/
Wickham, H., & Grolemund, G. (2017). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data (capítulo 3). O’Reilly Media. https://r4ds.had.co.nz/
12.3 Resumen
R proporciona una gran cantidad de funciones para la elaboración de gráficos estadísticos. En este capítulo, se describen algunos de los paquetes que contienen estas funciones y se ejemplifican varios tipos de gráficos.
12.4 Paquetes
Se presentan ejemplos de los paquetes graphics, ggplot2 y plotly.
12.4.1 graphics
graphics forma parte de la instalación base de R. Es muy versátil y permite construir una gran cantidad de tipos de gráficos. Sin embargo, estos graficos son estáticos y no ofrecen posibilidades de interacción con el usuario.
12.4.2 ggplot2
ggplot2 es un sistema para la creación declarativa de gráficos, basado en el libro The Grammar of Graphics, de Wilkinson et al.. El programador proporciona los datos, indica cuales variables mapear a las propiedades visuales (estéticas o aesthetics) de las geometrías y ggplot2 trata de encargarse del resto de los detalles.
De acuerdo con The Grammar of Graphics, los componentes de un gráfico son:
- Un conjunto de datos y un mapeo de sus variables a elementos visuales o aesthetics (x, y, color tamaño, forma, etc.).
- Una o más capas, cada una con un objeto geométrico, una transformación estadística, un ajuste de posición y, opcionalmente, su propio conjunto de datos y de mapeos a elementos visuales.
- Una escala para cada mapeo de elementos visuales.
- Un sistema de coordenadas.
- Una especificación de facets.
ggplot2 implementa estos componentes por medio de la función ggplot(), cuya sintaxis puede resumirse de la siguiente forma:
ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>ggplot2 provee más de 40 tipos de geometrías para gráficos (puntos, líneas, barras, histogramas, cajas, etc.) y los paquetes de extensión proporcionan aún más (ej. https://exts.ggplot2.tidyverse.org/gallery/). Para una explicación resumida de ggplot2, se recomienda Data visualization with ggplot2::Cheat Sheet.
12.4.3 plotly
plotly R es una biblioteca para gráficos interactivos que forma parte de la familia de Plotly, la cual incluye bibliotecas para otros lenguajes como JavaScript, Python, Julia, F# y MATLAB. Es adecuada, por ejemplo, cuando los gráficos van a utilizarse en la Web. Incluye una función llamada ggplotly() que permite convertir gráficos de ggplot2 a plotly.
12.4.4 Instalación y carga
Seguidamente, se muestran las instrucciones para instalar y cargar estos paquetes. El paquete graphics forma parte de la instalación base de R, por lo que no necesita ser instalado ni cargado explícitamente.
# Instalación de paquetes de graficación
install.packages("ggplot2")
install.packages("plotly")Adicionalmente, se cargan otros paquetes para importación y transformación de datos.
# Carga de otros paquetes
library(readr) # paquete para transformación de datos
library(dplyr) # paquete para transformación de datosExisten muchos otros paquetes de R para graficación, entre los que pueden mencionarse:
12.5 Conjuntos de datos para ejemplos
Para ejemplificar el uso de estos paquetes de graficación, se utilizarán varios conjuntos de datos. En esta sección, el contenido de estos conjuntos se muestra con el paquete DT, el cual despliega data frames como tablas en HTML con capacidades de filtrado, paginación, ordenamiento y otras.
# Instalación del paquete DT
install.packages("DT")Para cada conjunto de datos, se muestran los siguientes procesos del modelo de ciencia de datos: importación, transformación y visualización (en tablas).
12.5.1 mtcars
mtcars: Motor Trend Car Road Tests contiene datos de aspectos de diseño y consumo de combustible para 32 modelos de automóviles. Es uno de los conjuntos de datos contenidos en la instalación base de R, por lo que no es necesario importarlo desde una fuente externa.
Transformación:
Visualización en formato tabular:
12.5.2 Covid-19
Estos son datos publicados por el Ministerio de Salud de Costa Rica sobre la situación nacional de covid-19. Se distribuyen en archivos CSV, algunos correspondientes al nivel nacional y otros al nivel cantonal.
12.5.2.1 Datos nacionales
Este conjunto de datos contiene una observación por fecha y variables correspondientes a, entre otras, las cantidades de casos positivos, fallecidos, recuperados y activos a nivel nacional.
Importación:
# Importación de datos nacionales de covid-19
covid_nacional <-
read_delim(
file = "datos/ministerio-salud/covid/05_24_22_CSV_GENERAL.csv",
delim = ";",
col_select = c("FECHA", "positivos", "fallecidos", "RECUPERADOS", "activos")
)Transformación:
# Transformación de datos nacionales de covid-19
covid_nacional <-
covid_nacional %>%
select(fecha = FECHA,
positivos,
fallecidos,
recuperados = RECUPERADOS,
activos) %>%
mutate(fecha = as.Date(fecha, format = "%d/%m/%Y"))Visualización en formato tabular:
12.5.2.2 Casos positivos por cantón
Este conjunto de datos contiene una observación por cantón y variables correspondientes a la cantidad de casos positivos para cada fecha. En los ejemplos siguientes, se utiliza solamente la variable correspondiente a la fecha máxima.
Importación:
# Importación de casos positivos de covid-19 por cantón
covid_cantonal_positivos <-
read_delim(
file = "datos/ministerio-salud/covid/05_24_22_CSV_POSITIVOS.csv",
delim = ";",
locale = locale(encoding = "WINDOWS-1252"), # esto es para resolver el problema con las tildes
col_select = c("canton", "24/05/2022")
)Transformación:
# Transformación de casos positivos de covid-19 por cantón
covid_cantonal_positivos <-
covid_cantonal_positivos %>%
rename(positivos = '24/05/2022') %>% # renombramiento de columna
filter(!is.na(canton) & canton != "Otros") # borrado de filas con valor NA u "Otros" en la columna cantonVisualización en formato tabular:
12.5.3 diamonds
diamonds: Prices of over 50,000 round cut diamonds contiene los precios y otros atributos de casi 54000 diamantes. Este conjunto de datos está incluído en el paquete ggplot2.
12.6 Tipos de gráficos y ejemplos
En esta sección, se explican y ejemplifican varios tipos de gráficos estadísticos.
12.6.1 Gráficos de dispersión
Un gráfico de dispersión o scatterplot despliega los valores de dos variables numéricas de un conjunto de datos, como puntos en un sistema de coordenadas. El valor de una variable se despliega en el eje X y el de la otra variable en el eje Y. Variables adicionales pueden ser mostradas mediante atributos de los puntos, tales como tamaño, color y forma.
Los siguientes gráficos de dispersión presentan la relación entre las variables wt (peso en miles de libras) y mpg (rendimiento en millas por galón de combustible) del conjunto de datos mtcars.
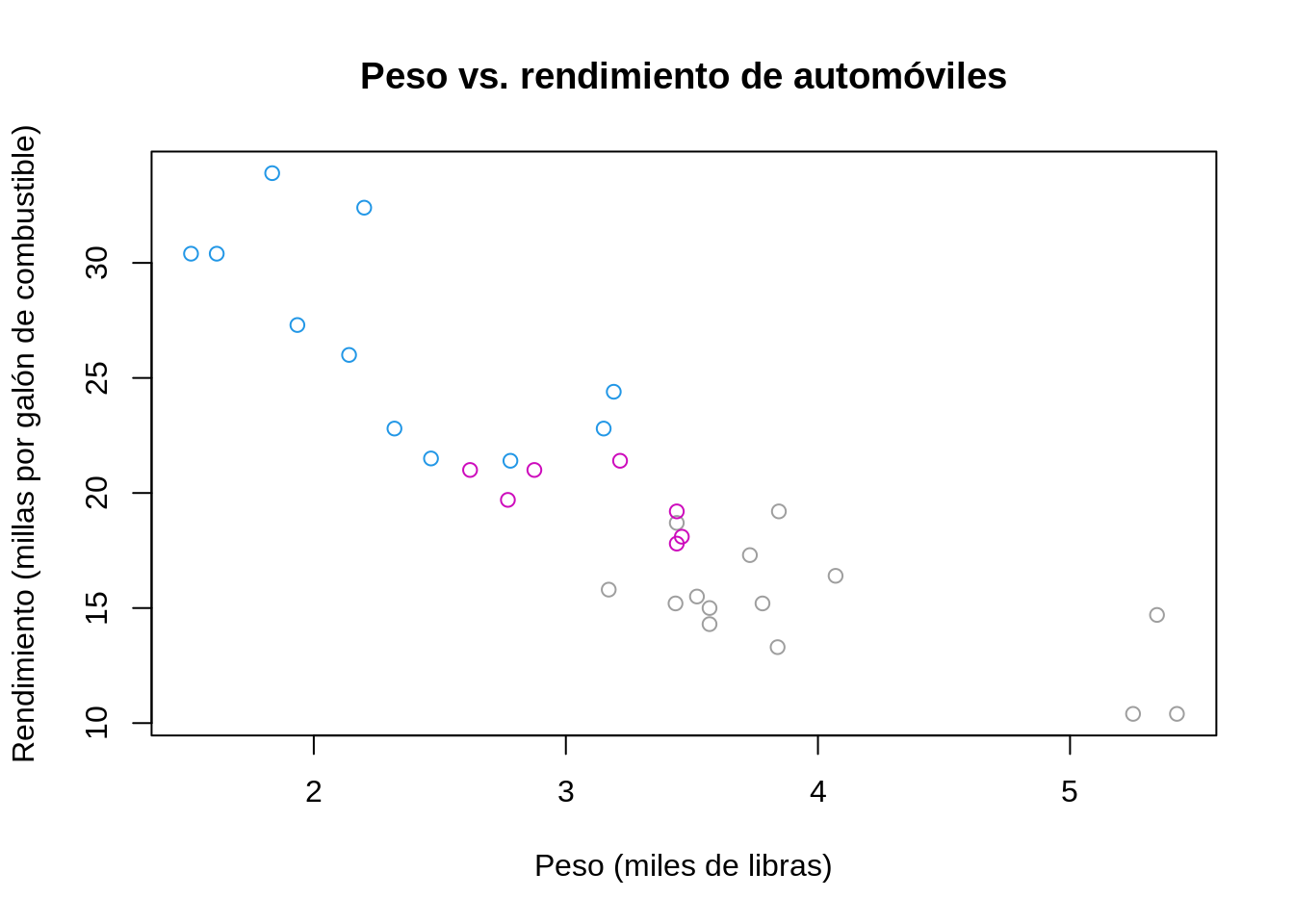
12.6.1.1 graphics
# graphics - gráfico de dispersión
plot(
x = mtcars$wt,
y = mtcars$mpg,
main = "Peso vs. rendimiento de automóviles",
xlab = "Peso (miles de libras)",
ylab = "Rendimiento (millas por galón de combustible)",
col = mtcars$cyl
)
12.6.1.2 ggplot2
# ggplot2 - gráfico de dispersión
ggplot2_mtcars_dispersion <-
mtcars %>%
ggplot(aes(x = wt, y = mpg)) +
geom_point(aes(text = rownames(mtcars), color = factor(cyl))) +
ggtitle("Peso vs. rendimiento de automóviles") +
xlab("Peso (miles de libras)") +
ylab("Rendimiento (millas por galón de combustible)") +
labs(color = "Cilindros")
#> Warning: Ignoring unknown aesthetics: text
ggplot2_mtcars_dispersion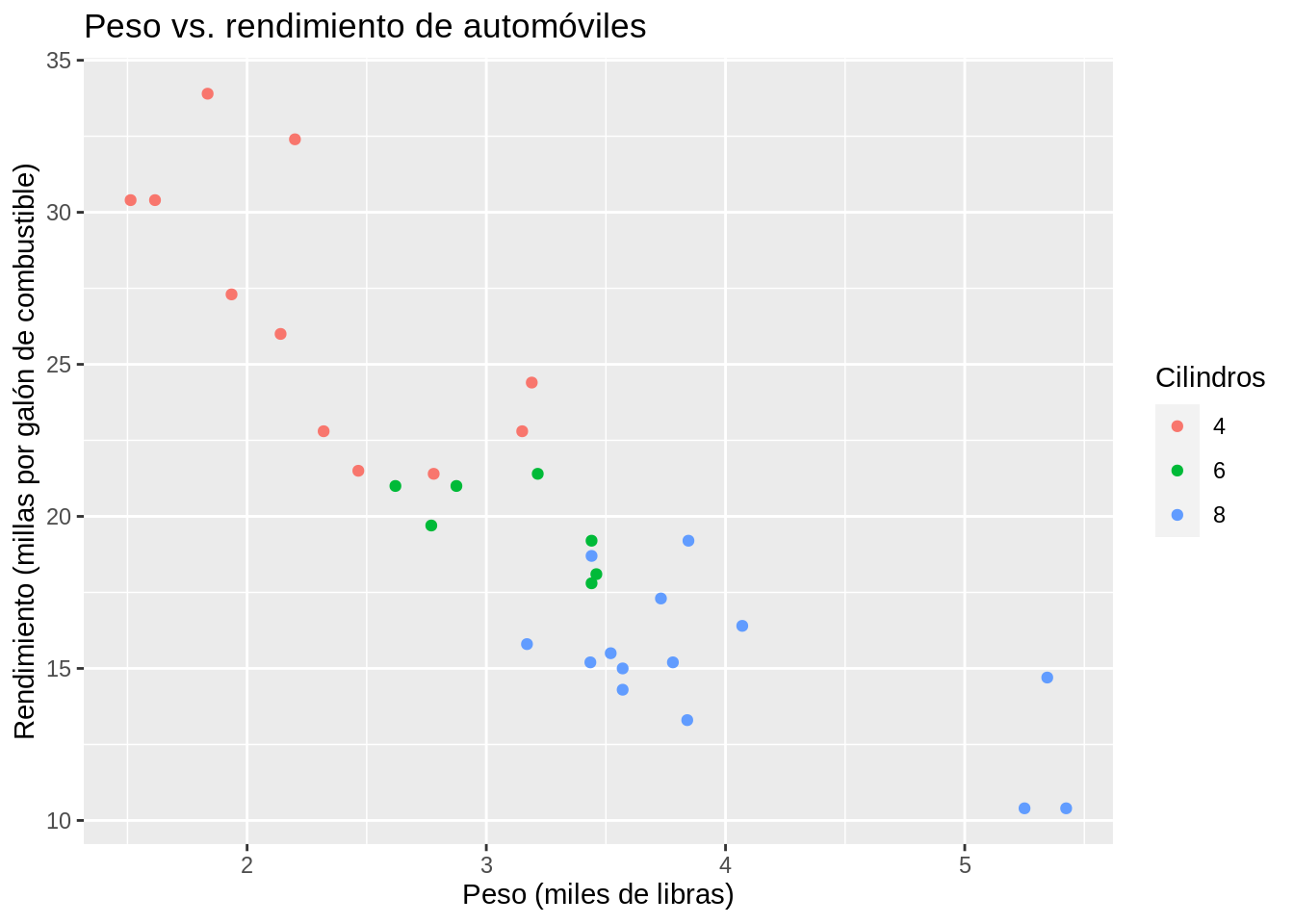
El argumento text de aes() en geom_pont() permite especificar texto que se despliega al colocar el ratón sobre un punto, cuando se utiliza la función ggplotly().
12.6.1.4 plotly
# plotly - gráfico de dispersión
mtcars %>%
plot_ly(x = ~ wt,
y = ~ mpg,
text = rownames(mtcars),
color = ~ factor(cyl)) %>% layout(
title = "Peso vs. rendimiento de automóviles",
xaxis = list(title = "Peso (miles de libras)"),
yaxis = list(title = "Rendimiento (millas por galón de combustible)")
) %>% layout(legend = list(title = list(text = "Cilindros"))) %>% config(locale = 'es')El argumento text de plot_ly() permite especificar texto que se despliega al colocar el ratón sobre un punto.
12.6.2 Gráficos de líneas
Un gráfico de líneas muestra información en la forma de puntos de datos, llamados marcadores (markers), conectados por segmentos de líneas rectas. Es similar a un gráfico de dispersión pero, además de los segmentos de línea, tiene la particularidad de que los datos están ordenados, usualmente con respecto al eje X. Los gráficos de línea son usados frecuentemente para mostrar tendencias a través del tiempo.
Los siguientes gráficos de línea muestran la evolución en el tiempo de los casos positivos, fallecidos, recuperados y activos de covid-19 en Costa Rica.
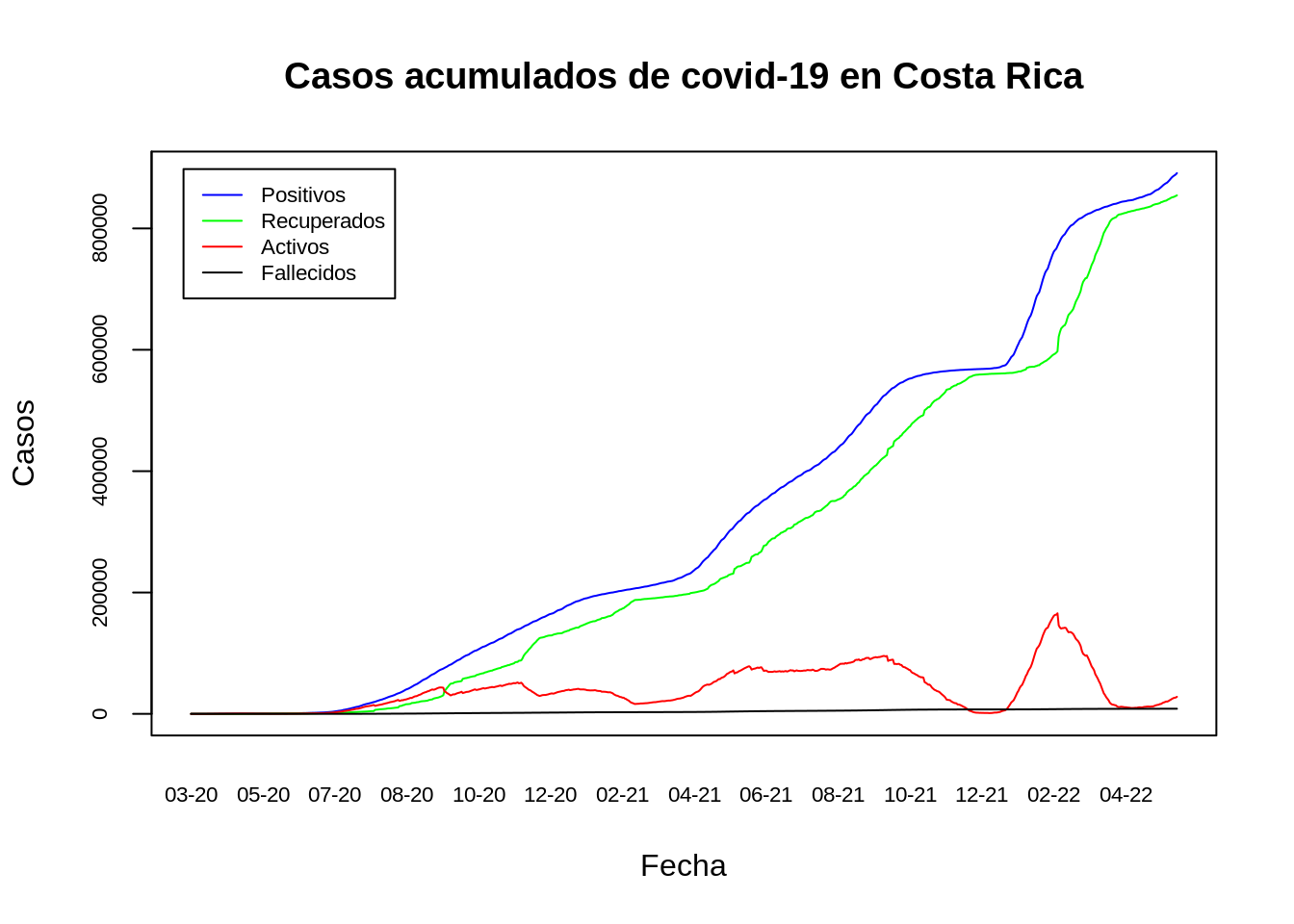
12.6.2.1 graphics
# graphics - gráfico de línea
plot(
covid_nacional$fecha,
covid_nacional$positivos,
type = "l",
xaxt = "n",
yaxt = "n",
main = "Casos acumulados de covid-19 en Costa Rica",
xlab = "Fecha",
ylab = "Casos",
col = "blue"
)
# Casos recuperados
lines(covid_nacional$fecha, covid_nacional$recuperados, col="green")
# Casos activos
lines(covid_nacional$fecha, covid_nacional$activos, col="red")
# Casos fallecidos
lines(covid_nacional$fecha, covid_nacional$fallecidos, col="black")
# Leyenda
legend(
x = "topleft",
inset = 0.03,
legend = c("Positivos", "Recuperados", "Activos", "Fallecidos"),
col = c("blue", "green", "red", "black"),
lty = 1,
cex = 0.7)
# Formato del eje X
axis(side = 1,
covid_nacional$fecha,
tick = FALSE,
format(covid_nacional$fecha, "%m-%y"),
cex.axis = .7)
# Formato del eje Y
axis(
side = 2,
covid_nacional$positivos,
labels = TRUE,
at = seq(0, 1000000, by = 200000),
cex.axis = .7
)
12.6.2.2 ggplot2
# ggplot2 - gráfico de línea
ggplot2_covid_nacional_linea <-
covid_nacional %>%
ggplot(aes(x = fecha, y = value, color = variable)) +
ggtitle("Casos acumulados de covid-19 en Costa Rica") +
xlab("Fecha") +
ylab("Casos") +
geom_line(aes(y = positivos, color = "Positivos")) +
geom_line(aes(y = recuperados, color = "Recuperados")) +
geom_line(aes(y = activos, color = "Activos")) +
geom_line(aes(y = fallecidos, color = "Fallecidos")) +
scale_colour_manual(
"",
values = c(
"Positivos" = "blue",
"Recuperados" = "green",
"Activos" = "red",
"Fallecidos" = "black"
)
)
ggplot2_covid_nacional_linea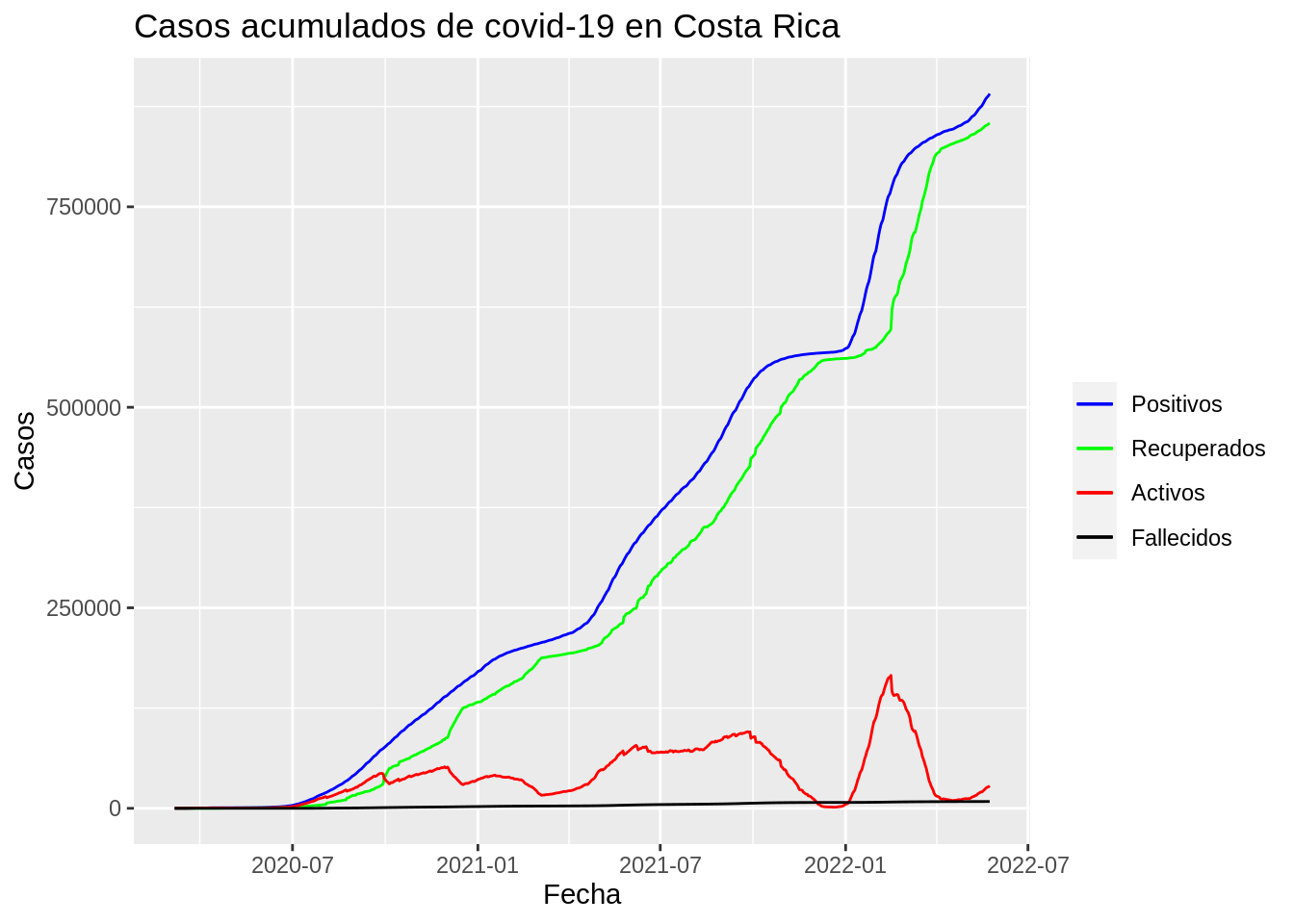
12.6.2.4 plotly
# plotly - gráfico de línea
covid_nacional %>%
plot_ly(
x = ~ fecha,
y = ~ positivos,
name = 'Positivos',
type = 'scatter',
mode = 'lines',
line = list(color = "blue")
) %>%
add_trace(
y = ~ recuperados,
name = 'Recuperados',
mode = 'lines',
line = list(color = "green")
) %>%
add_trace(
y = ~ activos,
name = 'Activos',
mode = 'lines',
line = list(color = "red")
) %>%
add_trace(
y = ~ fallecidos,
name = 'Fallecidos',
mode = 'lines',
line = list(color = "black")
) %>%
layout(
title = "",
yaxis = list(title = "Casos"),
xaxis = list(title = "Fecha"),
legend = list(x = 0.1, y = 0.9),
hovermode = "x unified"
)12.6.3 Gráficos de barras
Un gráfico de barras se compone de barras rectangulares con longitud proporcional a estadísticas (ej. frecuencias, promedios, mínimos, máximos) asociadas a una variable categórica. Las barras pueden ser horizontales o verticales y se recomienda que estén ordenadas según su longitud, a menos que exista un orden inherente a la variable categórica (ej. el orden de los días de la semana).
Es uno de los tipos de gráficos estadísticos más antiguos y comunes y tiene la ventaja de ser muy fácil de comprender.
12.6.3.1 ggplot2 - ggplotly()
En esta sección, se muestran ejemplos de gráficos de barras generados con el paquete ggplot2 y convertidos a gráficos de plotly mediante la función ggplotly().
12.6.3.1.1 Barras con transformaciones estadísticas
Los gráficos de barras y otros tipos de gráficos (ej. histogramas, gráficos de caja, líneas de ajuste) pueden requerir de alguna transformación estadística antes de presentar la información. Por ejemplo, el siguiente gráfico muestra la cantidad de diamantes por tipo de corte (cut). Nótese que este conteo no está presente en ninguna de las variables del conjunto de datos.
# ggplotly - Gráfico de barras simples con valores de conteo
ggplot2_barras_conteo <-
diamonds %>%
ggplot(aes(x = cut)) +
geom_bar() +
ggtitle("Cantidad de diamantes por tipo de corte") +
xlab("Corte") +
ylab("Cantidad") +
theme_minimal()
ggplotly(ggplot2_barras_conteo) %>% config(locale = 'es')El cálculo de la cantidad de diamantes por tipo de corte es un ejemplo de transformación estadística. La figura 12.1 muestra como se realiza este proceso para el gráfico anterior.
.](img/ggplot2-transformacion-estadistica.png)
Figure 12.1: Transformación estadística para un gráfico de barras de ggplot2. Imagen de Hadley Wickham.
El tipo de transformación se especifica en el argumento stat de geom_bar() el cual, por defecto, tiene el valor count. Es posible cambiar la transformación representada en el eje y, con la función stat().
El siguiente gráfico muestra la cantidad proporcional de cada corte de diamantes mediante el uso del argumento y = stat(prop).
# ggplotly - Gráfico de barras simples con valores proporcionales
ggplot2_barras_proporcion <-
diamonds %>%
ggplot(aes(x = cut, y = stat(prop), group = 1)) +
geom_bar() +
ggtitle("Proporciones de tipos de corte de diamantes") +
xlab("Corte") +
ylab("Proporción") +
theme_minimal()
ggplotly(ggplot2_barras_proporcion) %>% config(locale = 'es')Las barras pueden mostrar otras transformaciones estadísticas, como el promedio, con los argumentos stat = "summary" y fun.y = "mean" de geom_bar().
A continuación, se muestra el cálculo del precio promedio de diamantes por tipo de corte con la función summarise() y luego el gráfico de barras correspondiente.
# Precio promedio de diamantes por tipo de corte
diamonds %>%
group_by(clarity) %>%
summarise(
price_avg = mean(price, na.rm = TRUE),
n = n()
)
#> # A tibble: 8 × 3
#> clarity price_avg n
#> <ord> <dbl> <int>
#> 1 I1 3924. 741
#> 2 SI2 5063. 9194
#> 3 SI1 3996. 13065
#> 4 VS2 3925. 12258
#> 5 VS1 3839. 8171
#> 6 VVS2 3284. 5066
#> 7 VVS1 2523. 3655
#> 8 IF 2865. 1790
# ggplotly - Gráfico de barras simples con promedio de una variable
ggplot2_barras_promedio <-
diamonds %>%
ggplot(aes(x = cut, y = price)) +
geom_bar(stat = "summary", fun.y = "mean") +
ggtitle("Precio promedio de diamantes por tipo de corte") +
xlab("Corte") +
ylab("Precio promedio (dólares estadounidenses)") +
theme_minimal()
#> Warning: Ignoring unknown parameters: fun.y
ggplotly(ggplot2_barras_promedio) %>% config(locale = 'es')
#> No summary function supplied, defaulting to `mean_se()`12.6.3.1.2 Barras sin transformaciones estadísticas
En algunos conjuntos de datos, el valor que se quiere representar en la longitud de las barras ya está presente como una variable en el conjunto de datos, por lo que no es necesario que ggplot2 realice una transformación estadística. En este caso, a stat se le asigna el valor “identity” y al argumento y de aes() la variable que contiene el valor que quiere mostrarse en las barras.
En el siguiente gráfico, se muestra en las barras la cantidad de casos positivos por cantón, tomada de la columna positivos del conjunto de datos covid_cantonal_positivos.
# ggplotly - Gráfico de barras simples con valores de "identity"
ggplot2_barras_identity <-
covid_cantonal_positivos %>%
slice_max(positivos, n = 15) %>% # se seleccionan los 15 cantones con mayor cantidad de casos
ggplot(aes(x = reorder(canton, positivos), y = positivos)) +
geom_bar(stat = "identity") +
ggtitle("Cantidad de casos positivos de covid-19 por cantón") +
xlab("Cantón") +
ylab("Casos positivos") +
coord_flip() + # se invierten los ejes para generar barras horizontales
theme_minimal()
ggplotly(ggplot2_barras_identity) %>% config(locale = 'es')12.6.3.1.3 Barras apiladas
Al usar el argumento fill de aes() las barras pueden dividirse de acuerdo con una variable adicional, dando el efecto de barras apiladas.
# ggplotly - Gráfico de barras apiladas de cantidades
ggplot2_barras_apiladas_cantidad <-
diamonds %>%
ggplot(aes(x = cut, fill = clarity)) +
geom_bar() +
ggtitle("Cantidad de diamantes por tipo de corte y claridad") +
xlab("Corte") +
ylab("Cantidad") +
labs(fill = "Claridad") +
theme_minimal()
ggplotly(ggplot2_barras_apiladas_cantidad) %>% config(locale = 'es')El argumento position = "fill" de geom_bar() también genera barras apiladas, pero le asigna a todas las barras la misma longitud, facilitando así la comparación de proporciones.
# ggplotly - Gráfico de barras apiladas de proporciones
ggplot2_barras_apiladas_proporcion <-
diamonds %>%
ggplot(aes(x = cut, fill = clarity)) +
geom_bar(position = "fill") +
ggtitle("Proporciones de claridad por tipo de corte de diamantes") +
xlab("Corte") +
ylab("Proporción") +
labs(fill = "Claridad") +
theme_minimal()
ggplotly(ggplot2_barras_apiladas_proporcion) %>% config(locale = 'es')12.6.3.1.4 Barras agrupadas
El argumento position = "dodge" de geom_bar() genera barras agrupadas, facilitando así la comparación de valores individuales.
# ggplotly - Gráfico de barras agrupadas
ggplot2_barras_agrupadas <-
diamonds %>%
ggplot(aes(x = cut, fill = clarity)) +
geom_bar(position = "dodge") +
ggtitle("Cantidad de diamantes por tipo de corte y claridad") +
xlab("Corte") +
ylab("Cantidad") +
labs(fill = "Claridad") +
theme_minimal()
ggplotly(ggplot2_barras_agrupadas) %>% config(locale = 'es')12.6.4 Histogramas
Un histograma es una representación gráfica de la distribución de una variable numérica en forma de barras (llamadas en inglés bins). La longitud de cada barra representa la frecuencia de un rango de valores de la variable. La graficación de la distribución de las variables es, frecuentemente, una de las primeras tareas que se realiza cuando se explora un conjunto de datos.
12.6.4.1 ggplot2 - ggplotly()
Los siguientes histogramas muestran la distribución de las variables price (precio en dólares estadounidenses) y carat (peso en quilates).
# ggplotly - histograma
ggplot2_histograma_diamantes_precio <-
diamonds %>%
ggplot(aes(x = price)) +
geom_histogram(bins = 20) + # cantidad de barras (bins) +
ggtitle("Distribución del precio de diamantes") +
xlab("Precio (dólares estadounidenses)") +
ylab("Frecuencia") +
theme_minimal()
ggplotly(ggplot2_histograma_diamantes_precio) %>% config(locale = 'es')
# ggplotly - histograma
ggplot2_histograma_diamantes_peso <-
diamonds %>%
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.5) + # ancho de las barras +
ggtitle("Distribución del peso de diamantes") +
xlab("Peso (quilates)") +
ylab("Frecuencia") +
theme_minimal()
ggplotly(ggplot2_histograma_diamantes_peso) %>% config(locale = 'es') Debe tenerse en cuenta que los argumentos bins y binsize de geom_histogram() determinan en gran medida el aspecto del histograma, por lo que puede ser necesario probarlos con diferentes valores.
Un mismo histograma puede presentar la distribución de varios valores de una variable categórica, como se muestra en el siguiente gráfico.
# ggplotly - histograma con distribución de dos valores de una variable
ggplot2_histograma_diamantes_precio_claridad <-
diamonds %>%
filter(clarity == "SI2" | clarity == "VS1") %>%
ggplot(aes(x = price, fill = clarity)) +
geom_histogram(position = "identity", alpha = 0.4) + # ancho de las barras
ggtitle("Distribución del precio de diamantes de claridad 'SI2' y 'VS1'") +
xlab("Precio (dólares estadounidenses)") +
ylab("Frecuencia") +
theme_minimal()
ggplotly(ggplot2_histograma_diamantes_precio_claridad) %>% config(locale = 'es') 12.6.5 Diagramas de caja
Un diagrama de caja muestra información de una variable numérica a través de su mediana, sus cuartiles (Q1, Q2 y Q3) y sus valores atípicos.
La figura 12.2 muestra los componentes de un diagrama de caja.
.](img/640px-Diagrama_de_caja.jpg)
Figure 12.2: Componentes de un diagrama de caja. Imagen de Onkel Dagobert.
{kind=link}
12.6.5.1 ggplot2 - ggplotly()
El siguiente diagrama de caja muestra los valores de Q1, Q2 (mediana), Q3, mínimo y máximo de la variable mpg (millas por galón).
# ggplot2 - diagrama de caja
ggplot2_diagrama_caja_mtcars_mpg <-
mtcars %>%
ggplot(aes(y = mpg)) +
geom_boxplot() +
ylab("Rendimiento (millas por galón de combustible)") +
theme_minimal()
ggplotly(ggplot2_diagrama_caja_mtcars_mpg) %>% config(locale = 'es') El argumento x de la función aes() puede utilizarse para mostrar el diagrama anterior categorizado por otra variable.
# ggplot2 - diagrama de caja categorizado
ggplot2_diagrama_caja_mtcars_mpg_marchas <-
mtcars %>%
ggplot(aes(x = factor(gear), y = mpg)) +
geom_boxplot() +
xlab("Cantidad de marchas") +
ylab("Rendimiento (millas por galón de combustible)") +
theme_minimal()
ggplotly(ggplot2_diagrama_caja_mtcars_mpg_marchas) %>% config(locale = 'es')12.6.6 Gráficos de pastel
Un gráfico de pastel representa porcentajes y porciones en secciones (slices) de un círculo. Son muy populares, pero también criticados debido a la dificultad del cerebro humano de comparar áreas de sectores circulares, por lo que algunos expertos recomiendan sustituirlos por otros tipos de gráficos como, por ejemplo, gráficos de barras.
En los siguientes ejemplos, se utiliza un data frame llamado diamonds_cut que contiene el porcentaje que representa la cantidad de diamantes de cada tipo de corte (cut) con respecto al total.
n <- nrow(diamonds)
diamonds_cut <-
diamonds %>%
group_by(cut) %>%
summarise(cut_count = n(), cut_pct = round(cut_count/n * 100, digits = 1))Seguidamente, se presentan ejemplos de gráficos de pastel elaborados con ggplot2 y plotly.
12.6.6.1 ggplot2
# ggplot2 - gráfico de pastel
diamonds_cut %>%
ggplot(aes(x = factor(1), y = cut_pct, fill = cut)) +
geom_bar(stat = "identity", width = 1) +
coord_polar("y") +
geom_text(aes(label = paste(cut_pct, "%")), position = position_stack(vjust=0.5)) +
scale_fill_brewer(palette = "Spectral") +
theme_void()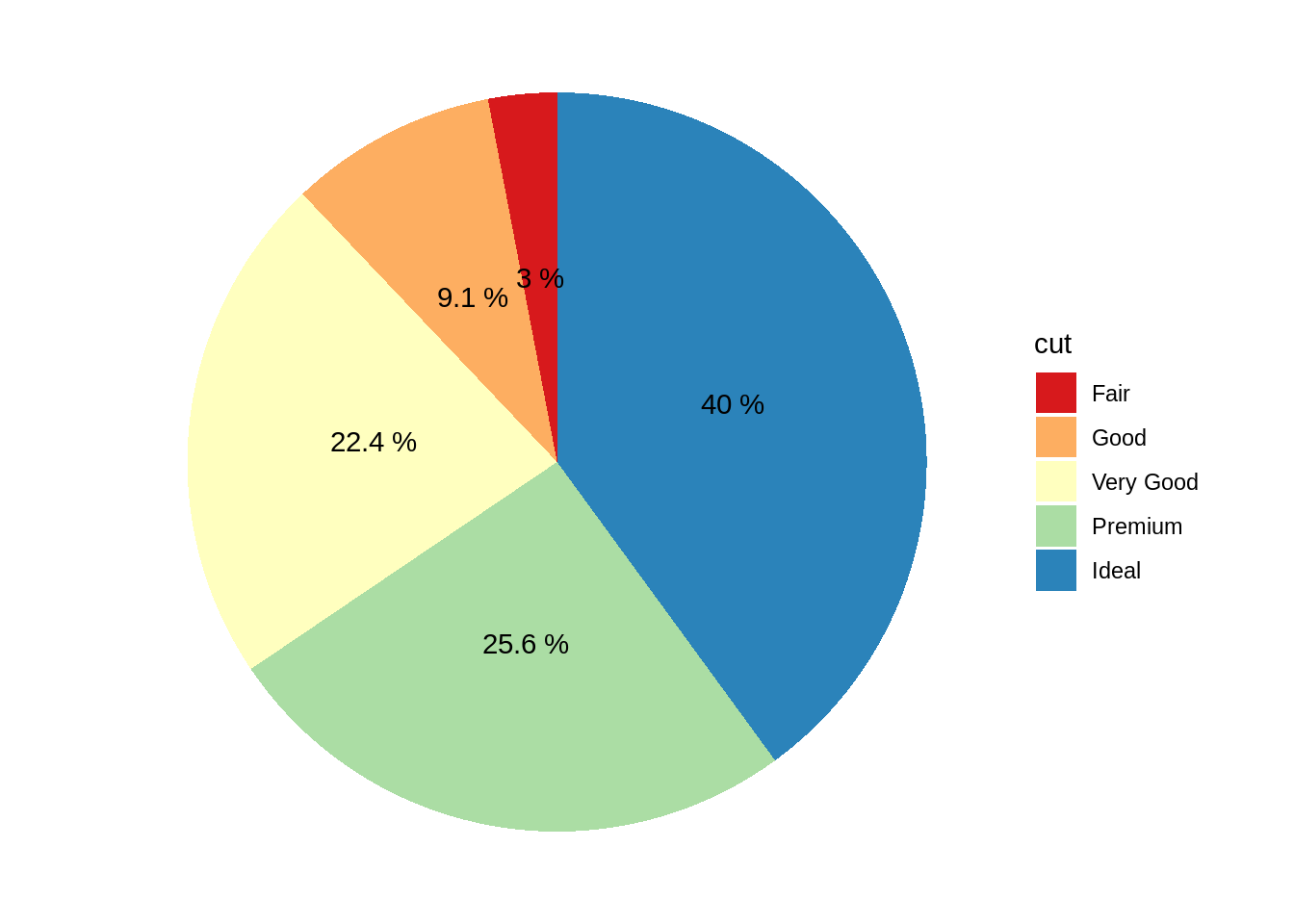
No es posible traducir un gráfico de pastel de ggplot2 a plotly mediante ggplotly() debido que esa función aún no cuenta con soporte para coord_polar().
12.6.6.2 plotly
# ggplot2 - gráfico de pastel
diamonds_cut %>%
plot_ly(
labels = ~ cut,
values = ~ cut_count,
type = 'pie',
textposition = 'inside',
textinfo = 'label+percent',
hoverinfo = 'text',
text = ~ paste(cut_count, ' diamantes')
) %>%
layout(title = 'Proporciones de tipos de corte de diamantes') %>%
config(locale = 'es')12.6.7 Facets
La función aes() es una forma de introducir variables adicionales en gráficos. Otra forma es dividir el gráfico en facets, los cuales son subgráficos que despliegan subconjuntos de los datos.
Los facets se implementan mediante las funciones facet_wrap() y facet_grid().
12.6.7.1 facet_wrap()
facet_wrap() divide el gráfico de acuerdo con una sola variable. El primer argumento es una formula, la cual se crea con el caracter ~ seguido por el nombre de una variable, la cual debe ser discreta.
diamonds %>%
ggplot(aes(x = carat, y = price)) +
geom_point() +
xlab("Peso (quilates)") +
ylab("Precio (dólares estadounidenses)") +
facet_wrap(~ cut, nrow = 2)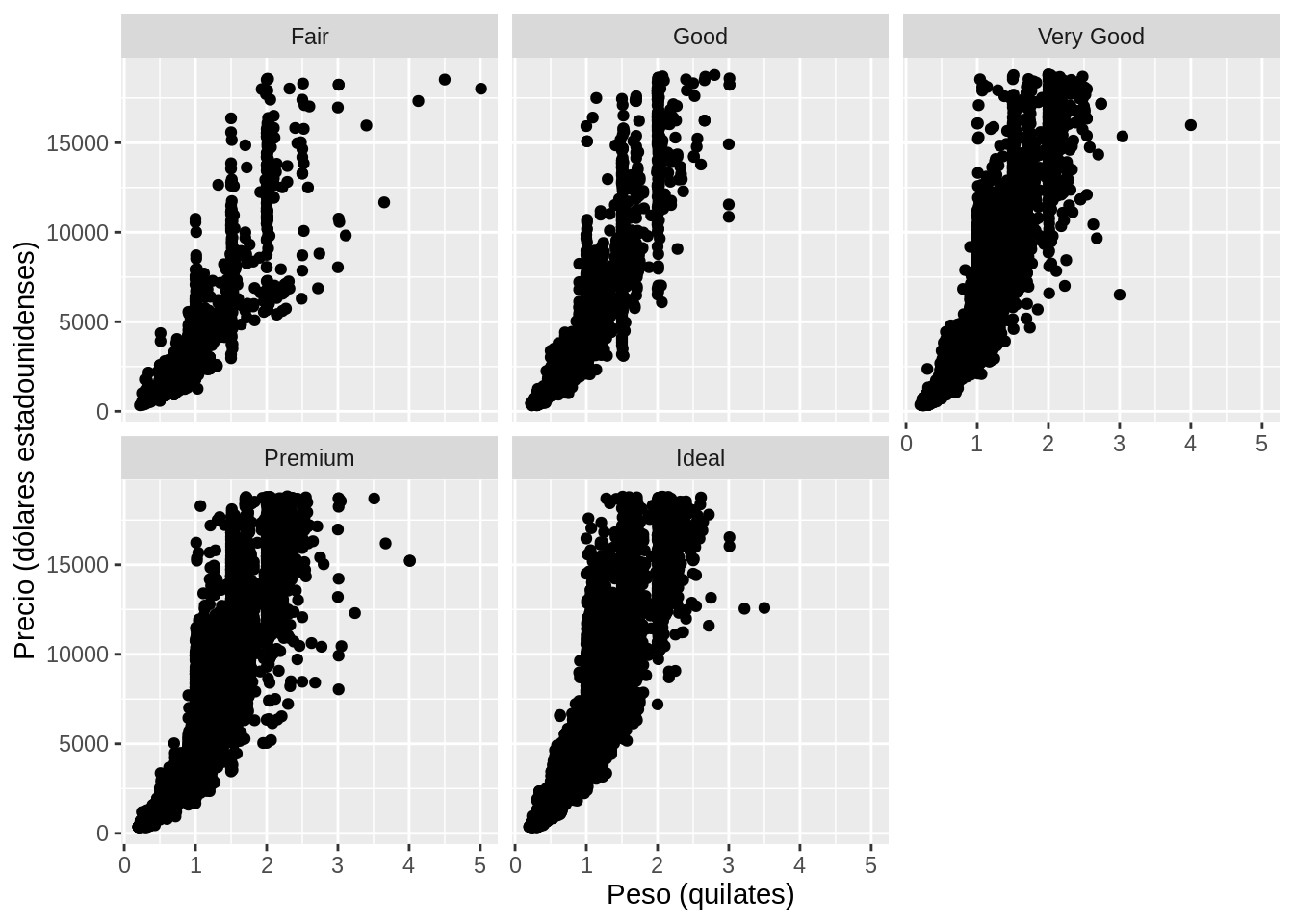
12.6.7.2 facet_grid()
facet_grid() genera los subgráficos con la combinación de dos variables. El primer argumento es también una fórmula, la cual contiene dos variables separadas por ~.
ggplot(data = diamonds) +
geom_point(mapping = aes(x = carat, y = price)) +
xlab("Peso (quilates)") +
ylab("Precio (dólares estadounidenses)") +
facet_grid(cut ~ clarity)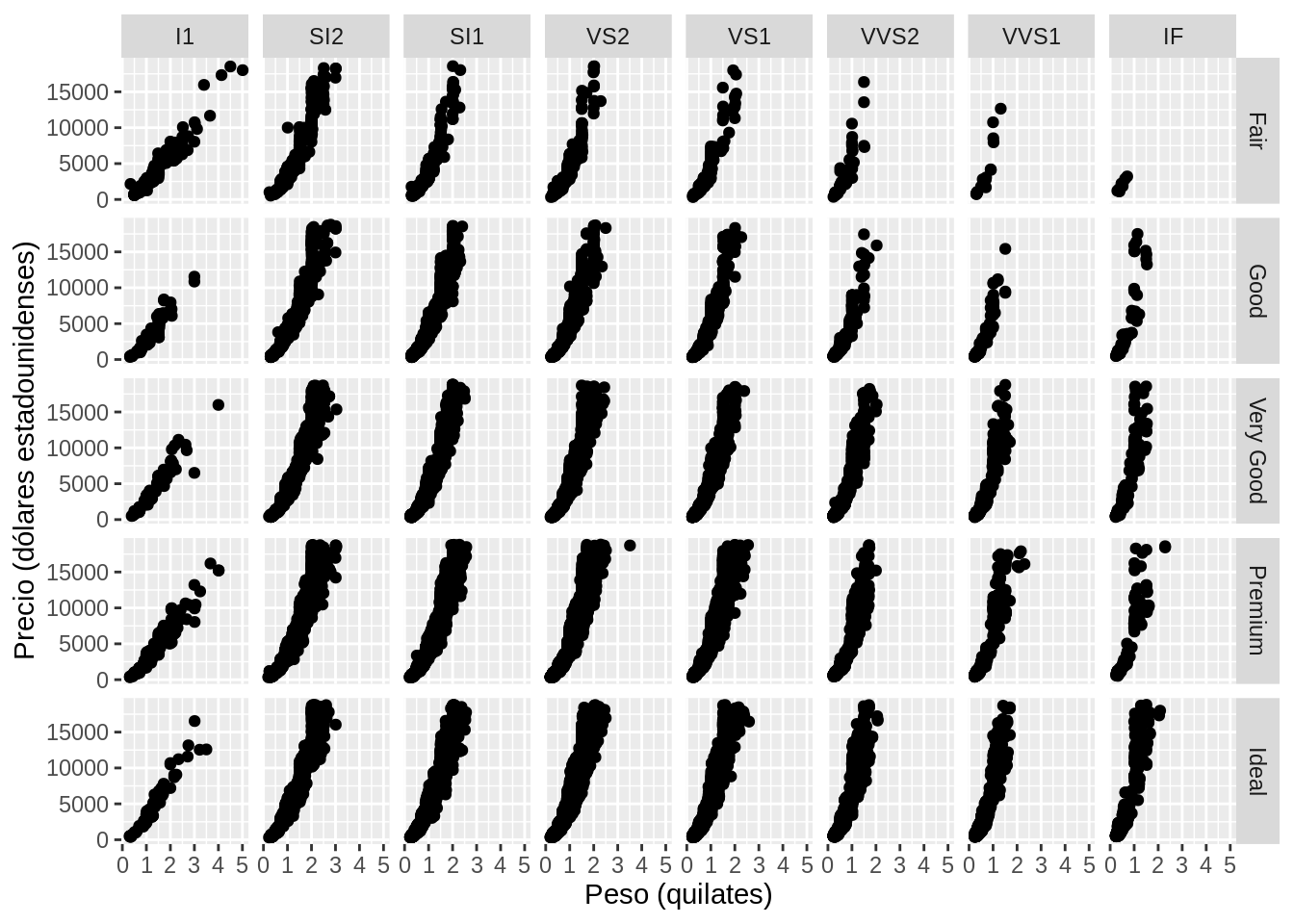
12.7 Recursos de interés
DT: An R interface to the DataTables library. (s. f.). Recuperado 21 de mayo de 2022, de https://rstudio.github.io/DT/
Healy, Y. H. and C. (s. f.). From data to Viz | Find the graphic you need. Recuperado 20 de marzo de 2022, de https://www.data-to-viz.com/
RStudio. (2017). Data visualization with ggplot2::Cheat Sheet. https://raw.githubusercontent.com/rstudio/cheatsheets/main/data-visualization.pdf
Wickham, H. (2010). A Layered Grammar of Graphics. Journal of Computational and Graphical Statistics, 19(1), 3-28. https://doi.org/10.1198/jcgs.2009.07098